predict
Label new data using semi-supervised self-trained classifier
Description
Examples
Use both labeled and unlabeled data to train a SemiSupervisedSelfTrainingModel object. Label new data using the trained model.
Randomly generate 15 observations of labeled data, with 5 observations in each of three classes.
rng('default') % For reproducibility labeledX = [randn(5,2)*0.25 + ones(5,2); randn(5,2)*0.25 - ones(5,2); randn(5,2)*0.5]; Y = [ones(5,1); ones(5,1)*2; ones(5,1)*3];
Randomly generate 300 additional observations of unlabeled data, with 100 observations per class.
unlabeledX = [randn(100,2)*0.25 + ones(100,2);
randn(100,2)*0.25 - ones(100,2);
randn(100,2)*0.5];Fit labels to the unlabeled data by using a semi-supervised self-training method. The function fitsemiself returns a SemiSupervisedSelfTrainingModel object whose FittedLabels property contains the fitted labels for the unlabeled data and whose LabelScores property contains the associated label scores.
Mdl = fitsemiself(labeledX,Y,unlabeledX)
Mdl =
SemiSupervisedSelfTrainingModel with properties:
FittedLabels: [300×1 double]
LabelScores: [300×3 double]
ClassNames: [1 2 3]
ResponseName: 'Y'
CategoricalPredictors: []
Learner: [1×1 classreg.learning.classif.CompactClassificationECOC]
Properties, Methods
Randomly generate 150 observations of new data, with 50 observations per class. For the purposes of validation, keep track of the true labels for the new data.
newX = [randn(50,2)*0.25 + ones(50,2);
randn(50,2)*0.25 - ones(50,2);
randn(50,2)*0.5];
trueLabels = [ones(50,1); ones(50,1)*2; ones(50,1)*3];Predict the labels for the new data by using the predict function of the SemiSupervisedSelfTrainingModel object. Compare the true labels to the predicted labels by using a confusion matrix.
predictedLabels = predict(Mdl,newX); confusionchart(trueLabels,predictedLabels)
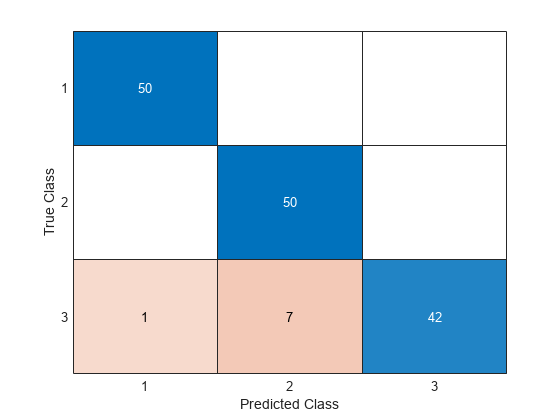
Only 8 of the 150 observations in newX are mislabeled.
Input Arguments
Output Arguments
Version History
Introduced in R2020b