Explain Model Predictions for Regression Models Trained in Regression Learner App
Understanding how some machine learning models make predictions can be difficult. Interpretability tools help reveal how predictors contribute (or do not contribute) to model predictions. You can also use these tools to validate whether a model uses the correct evidence for its predictions, and find model biases that are not immediately apparent.
Global and Local Interpretation Plots
The Regression Learner app provides several types of global interpretation plots that explain how a trained model makes predictions for the entire data set. For example, you can use global plots to effectively compare how different machine learning models make predictions on the same data set. The permutation importance plot uses permutations of predictor data to show the relative impact of predictors on model predictions. Global Shapley plots use Shapley values derived from game theory to visualize the impact of individual predictors on model predictions for a set of query points. The partial dependence plot (PDP), another global interpretation plot, shows the relationship between a predictor and the model prediction by marginalizing out the effect of the other predictors.
The following table describes the global interpretation plots that are available for a data set that contains p predictors. q represents the number of query points.
| Plot | Usage | Type | X-axis | Y-axis | Number of Possible Plots | Number of Shapley Values Summarized |
|---|---|---|---|---|---|---|
Permutation Importance (since R2025a) | Identify which predictors have the largest (or smallest) average impact on predicted response values. | Bar chart | Mean permutation importance values | Predictors | 1 | Not applicable |
Shapley Importance (since R2024b) | Identify which predictors have the largest (or smallest) average impact on predicted response values. | Bar chart | Mean of absolute Shapley values | Predictors | 1 | p × q |
Shapley Summary (since R2024b) | Interpret the positive or negative impact of individual predictors on the predicted response values by plotting the Shapley values of a set of query points. Color the query points according to relative predictor value. | Swarm or box chart | Shapley value | Predictors | 1 | p × q |
Shapley Dependence (since R2024b) | Interpret the positive or negative impact of a predictor of interest on the predicted response values by plotting the Shapley values versus the predictor values for a set of query points. Optionally color the query points according to the values of a second predictor. | Scatter or box chart | Predictor value | Shapley value for x-axis predictor | p2 | q |
Partial Dependence (since R2022b) | Visualize the marginal effect of a predictor of interest on the predicted response across the predictor values. | Line plot | Predictor value | Predicted response values | p | Not applicable |
The app also offers two types of local interpretation plots that allow you to examine model predictions for a specific query point of interest. For example, you can use a local interpretation plot to examine a counterintuitive model prediction for an individual observation.
Generate a Local Shapley plot to compute Shapley values for a query point and identify which predictors have the largest (or smallest) impact on the model predictions for that point.
Generate a LIME (local interpretable model-agnostic explanations) plot to fit a simple interpretable model for a query point and identify which predictors have the largest (or smallest) impact on the model predictions for that point.
When you create a global or local interpretation plot, you can export the plot and the results to the workspace. However, you cannot export partial dependence plot results from the app. For an example of how to extract PDP results in MATLAB®, see Extract Partial Dependence Estimates from Plots
Explain Local Model Predictions Using LIME Values
Use LIME (local interpretable model-agnostic explanations) to interpret a prediction for a query point by fitting a simple interpretable model for the query point. The simple model acts as an approximation for the trained model and explains model predictions around the query point. The simple model can be a linear model or a decision tree model. You can use the estimated coefficients of a linear model or the estimated predictor importance of a decision tree model to explain the contribution of individual predictors to the prediction for the query point.
After you train a model in Regression Learner, select the model in the
Models pane. On the Explain tab, in
the Local Explanations section, click
LIME. The app opens a new tab. In the left plot or table,
select a query point. In the right plot or table, the app displays the LIME values
corresponding to the query point. The app uses the lime
function to compute the LIME values. When computing LIME values, the app uses the
full model, trained on the training data set (which includes validation data, but
excludes test data).
Note
Regression Learner does not support LIME explanations for models trained after applying principal component analysis (PCA).

Select Query Point
To select a query point, you can use various controls.
To the right of the LIME plots, under Data, choose whether to select a query point from the Training set data or Test set data. The training set refers to the data used to train the full model.
Above the left plot, under Select Query Point, choose whether to select a query point from a plot (Plot) or a table (Table). If using a plot, click a point in the plot to designate the associated observation as the query point. If using a table, click a row in the table to select the associated observation as the query point.
Alternatively, select a query point using the index of the observation in the selected data set. To the right of the LIME plots, under Query Point, enter the observation index.
To make selecting a query point from a plot easier, you can change the plot display by using the controls below the left plot. You can specify the plot type, select the x-axis and y-axis variables, and choose the values to display (such as true responses, predicted responses, and errors).
After selecting a query point, you can expand the LIME Explanations display by hiding the Select Query Point display. To the right of the LIME plots, under Data, clear the Show query points check box.
Plot LIME Explanations
Given a query point, view its LIME values by using the LIME Explanations display. Choose whether to view the results using a bar graph (Plot) or a table (Table). The table includes the predictor values at the query point.
The meaning of the LIME values depends on the type of LIME model used. To the right of the LIME plots, in the Simple Model section under LIME Options, specify the type of simple model to use for approximating the behavior of the trained model.
If you use a
Linearsimple model, the LIME values correspond to the coefficient values of the simple model. The bar graph shows the coefficients, sorted by their absolute values. For each categorical predictor, the software creates one less dummy variable than the number of categories, and the bar graph displays only the most important dummy variable. You can check the coefficients of the other dummy variables using theSimpleModelproperty of the exported results object. For more information, see Export LIME Results.If you use a
Treesimple model, the LIME values correspond to the estimated predictor importance values of the simple model. The bar graph shows the predictor importance values, sorted by their absolute values. The bar graph shows LIME values only for the subset of predictors included in the simple model.
Below the display of the LIME explanations, the app shows the query point predictions for the trained model (for example, Model 1 prediction) and the simple model (for example, LIME model prediction). If the two predictions are not close, the simple model is not a good approximation of the trained model at the query point. You can change the simple model so that it better matches the trained model at the query point by adjusting LIME options.
Adjust LIME Options
To adjust LIME options, you can use various controls to the right of the LIME plots, under LIME Options.
Under Simple Model, you can set these options:
Simple model — Specify the type of simple model to use for approximating the behavior of the trained model. Choose between a linear model, which uses
fitrlinear, and a decision tree, which usesfitrtree. For more information, seeSimpleModelType.In Regression Learner, linear simple models use a
BetaTolerancevalue of 0.00000001.Max num predictors — Specify the maximum number of predictors to use for training the simple model. For a linear simple model, this value indicates the maximum number of predictors to include in the model, not counting expanded categorical predictors. Unimportant predictors are not included in the simple model. For a tree simple model, this value indicates the maximum number of decision splits (or branch nodes) in the tree, which might cause the model to include fewer predictors than the specified maximum. For more information, see
numImportantPredictors.Kernel width — Specify the width of the kernel function used to fit the simple model. Smaller kernel widths create LIME models that focus on data samples near the query point. For more information, see
KernelWidth.
Under Synthetic Predictor Data, you can set these options:
Num data samples — Specify the number of synthetic data samples to generate for training the simple model. For more information, see
NumSyntheticData.Data locality — Specify the locality of the data to use for synthetic data generation. A
Globallocality uses all observations in the training data set, and aLocallocality uses the k-nearest neighbors of the query point. (Recall that the training data set contains the data used to train the full model and does not include any test set data.) For more information, seeDataLocality.Num neighbors — Specify the number of k-nearest neighbors for the query point. This option is valid only when the data locality is
Local. For more information, seeNumNeighbors.
For more information on the LIME algorithm and how synthetic data is used, see LIME.
Perform What-If Analysis
After computing the LIME results for a query point, you can perform what-if analysis and compare the LIME results for the original query point to the results for a custom query point. For example, you can see whether the important predictors change when the query point predictor values deviate slightly from their original values.
To the right of the LIME plots, under Query Point, select What-if analysis. The app creates a table that shows the predictor values for the original query point and a custom query point. Manually specify the predictor values of the custom query point by editing the Custom Value table entries. To better see the table entries, you can increase the width of the plot options panel by using the plus button + at the top of the panel.
After you specify a custom query point, the app updates the display of the LIME results.
The query point plot shows the original query point as a black circle and the custom query point as a green square.
The LIME explanations bar graph shows the LIME values for the original and custom query points, and differentiates the two sets of bars by using different colors and edge styles.
The LIME explanations table includes the LIME and predictor values for both query points.
Below the display of the LIME explanations, you can find the trained model and simple model predictions for both query points. Ensure that the two predictions for the custom query point are close. Otherwise, the simple model is not a good approximation of the trained model at the custom query point.

Export LIME Results
After computing LIME values, you can export your results by using options in the Export section on the Explain tab.
To export the LIME explanations bar graph to a figure, click Export Plot and select Export Plot to Figure.
To export the LIME explanations table and the query point model explainer object to the workspace, click Export Plot and select Export Plot Data. In the Export LIME Plot Data dialog box, edit the name of the exported variable, if necessary, and click OK. The app creates a structure array that contains the LIME results table and the explainer object. If you specify a custom query point by using what-if analysis, the model explainer object corresponds to the custom query point. For more information on the explainer object, see
lime.
Explain Global Model Predictions Using Permutation Importance Plot
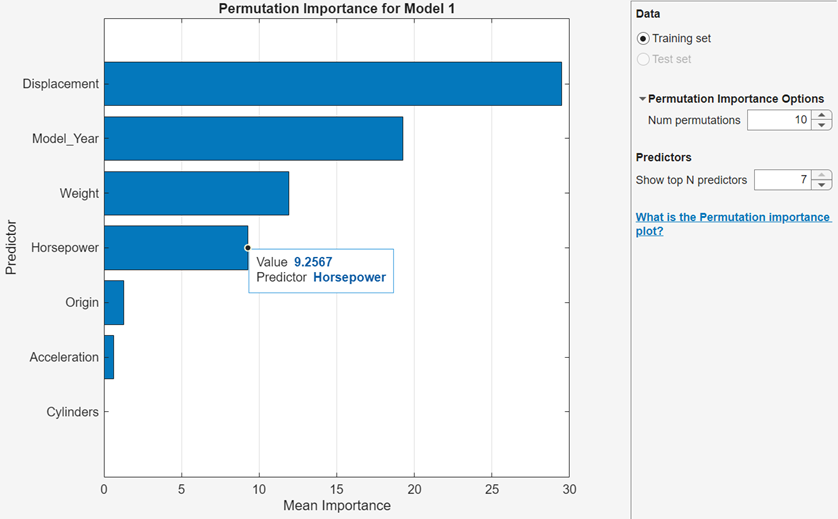
Use the mean permutation importance values of predictors to interpret which predictors have the largest (or smallest) average impact on model predictions. For regression models, predictions are response values. The app computes a permutation importance value for each predictor by permuting the values in the predictor and comparing the model resubstitution loss with the original predictor to the loss with the permuted predictor. A large increase in the model loss with the permuted predictor indicates that the predictor is important. Therefore, the mean of the permutation importance values for a predictor over several permutations provides a measure of the predictor's importance for model predictions.
After you train a model in Regression Learner, select the model in the
Models pane. On the Explain tab, in
the Global Importance section, click Permutation
Importance. The app opens a new tab and computes the mean importance
values for a set of query points using the permutationImportance function. When the computation is complete,
the app displays a bar chart of the mean importance values for the top predictors,
sorted from highest to lowest. Point to a bar to display information about the mean
importance value.
Note
Regression Learner does not support permutation importance plots for the following linear regression models: Interactions Linear, Robust Linear, and Stepwise Linear.
The loss function used by the app depends on the model type. For more information,
see LossFun and the
Algorithms section of permutationImportance. When computing mean importance values, the
app uses the full model, trained on the training data set (which includes validation
data, but excludes test data). If you have tested the model on test data, you can
display mean importance values by selecting Test set under
Data, at the right of the plot.
If the trained model includes many predictors, you can choose to display only the most important predictors in the bar graph. To the right of the plot, under Predictors, specify the number of important predictors to show. The app displays the specified number of predictors with the largest mean importance values.
To adjust the number of permutations that the app uses to calculate the mean
importance values, specify a value in the Num permutations box
under Permutation Importance Options. For more information on
the algorithms used to compute mean permutation importance values, see the Algorithms section of the
permutationImportance reference page.
Export Permutation Importance Results
After computing permutation importance values, you can export your results by using options in the Export section on the Explain tab.
To export the bar graph to a figure, click Export Plot and select Export Plot to Figure.
To export the permutation importance results to the workspace, click Export Plot and select Export Plot Data. In the Export Permutation Importance Plot dialog box, edit the name of the exported variable, if necessary, and click OK. The app creates a structure array that contains the following tables:
Importance— Mean and standard deviation of the permutation importance for each predictorImportancePerPermutation— Mean permutation importance value of each predictor for each permutation
Explain Local Model Predictions Using Shapley Values
Use the Shapley value of a predictor for a query point to explain the deviation of the query point prediction from the average prediction, due to the predictor. For regression models, predictions are response values. For a query point, the sum of the Shapley values for all predictors corresponds to the total deviation of the prediction from the average.
After you train a model in Regression Learner, select the model in the
Models pane. On the Explain tab, in
the Local Explanations section, click Local
Shapley. The app opens a new tab. In the left plot or table, select a
query point. In the right plot or table, the app displays the Shapley values
corresponding to the query point. The app uses the shapley
function to compute the Shapley values. When computing Shapley values, the app uses
the full model, trained on the training data set (which includes validation data,
but excludes test data).
Note
Regression Learner does not support local Shapley explanations for models trained after applying principal component analysis (PCA).

Select Query Point
To select a query point, you can use various controls.
To the right of the Shapley plots, under Data, choose whether to select a query point from the Training set data or Test set data. The training set refers to the data used to train the full model, and does not include any test set data.
Above the left plot, under Select Query Point, choose whether to select a query point from a plot (Plot) or a table (Table). If using a plot, click a point in the plot to designate the associated observation as the query point. If using a table, click a row in the table to select the associated observation as the query point.
Alternatively, select a query point using the index of the observation in the selected data set. To the right of the Shapley plots, under Query Point, enter the observation index.
To make selecting a query point from a plot easier, you can change the plot display by using the controls below the left plot. You can specify the plot type, select the x-axis and y-axis variables, and choose the values to display (such as true responses, predicted responses, and errors).
After selecting a query point, you can expand the Shapley Explanations display by hiding the Select Query Point display. To the right of the Shapley plots, under Data, clear the Show query points check box.
Plot Shapley Explanations
Given a query point, view its Shapley values by using the Shapley Explanations display. Each Shapley value explains the deviation of the prediction for the query point from the average prediction, due to the corresponding predictor. Choose whether to view the results using a bar graph (Plot) or a table (Table). The horizontal bar graph shows the Shapley values for all predictors, sorted by their absolute values. The table includes the predictor values at the query point along with the Shapley values. Below the display of the Shapley explanations, the app shows the query point prediction and the average model prediction. The sum of the Shapley values equals the difference between the two predictions.
If the trained model includes many predictors, you can choose to display only the most important predictors in the bar graph. To the right of the Shapley plots, under Shapley Plot, specify the number of important predictors to show in the Shapley Explanations bar graph. The app displays the specified number of Shapley values with the largest absolute value.
Adjust Shapley Options
To adjust Shapley options, you can use various controls to the right of the Shapley plots. Under Shapley Options, you can set these options:
Num data samples — Specify the number of observations sampled from the training data set to use for Shapley value computations. (Recall that the training data set contains the data used to train the full model, and does not include any test set data.)
When the training data set has over 1000 observations, the Shapley value computations might be slow. For faster computations, consider using a smaller number of data samples. For more information, see NumObservationsToSample.
Method — Specify the algorithm to use when computing Shapley values. The
Interventionaloption computes Shapley values with an interventional value function. When Max num subsets mode isAuto, the app uses the Kernel SHAP, Linear SHAP, or Tree SHAP algorithm, depending on the trained model type and other specified options. When you set Max num subsets mode toManual, the app uses the KernelSHAP algorithm. TheConditionaloption always uses the extension to the Kernel SHAP algorithm with a conditional value function. For more information, seeMethod.Max num subsets mode — Allow the app to choose the maximum number of predictor subsets automatically, or specify a value manually. You can check the number of predictor subsets used by querying the
NumSubsetsproperty of the exported results object. For more information, see Export Shapley Results.Manual max num subsets — When you set Max num subsets mode to
Manual, specify the maximum number of predictor subsets to use for Shapley value computations. In this case, the app uses the Kernel SHAP algorithm when Method isInterventional, and the extension to the Kernel SHAP algorithm when Method isConditional. For more information, seeMaxNumSubsets.
For more information on the algorithms used to compute Shapley values, see Shapley Values for Machine Learning Model.
Perform What-If Analysis
After computing the Shapley results for a query point, you can perform what-if analysis and compare the Shapley results for the original query point to the results for a custom query point. For example, you can see whether the important predictors change when the query point predictor values deviate slightly from their original values.
To the right of the Shapley plots, under Query Point, select What-if analysis. The app creates a table that shows the predictor values for the original query point and a custom query point. Manually specify the predictor values of the custom query point by editing the Custom Value table entries. To better see the table entries, you can increase the width of the plot options panel by using the plus button + at the top of the panel.
After you specify a custom query point, the app updates the display of the Shapley results.
The query point plot shows the original query point as a black circle and the custom query point as a green square.
The Shapley explanations bar graph shows the Shapley values for the original and custom query points, and differentiates the two sets of bars by using different colors and edge styles.
The Shapley explanations table includes the Shapley and predictor values for both query points.
Below the display of the Shapley explanations, you can find the model predictions for both query points. For easy comparison, the app lists the average model prediction twice, once below each query point prediction.

Export Shapley Results
After computing Shapley values, you can export your results by using options in the Export section on the Explain tab.
To export the Shapley bar graph to a figure, click Export Plot and select Export Plot to Figure.
To export the Shapley explanations table and the query point model explainer object to the workspace, click Export Plot and select Export Plot Data. In the Export Local Shapley Plot Data dialog box, edit the name of the exported variable, if necessary, and click OK. The app creates a structure array that contains the Shapley results table and the explainer object. If you specify a custom query point by using what-if analysis, the model explainer object corresponds to the custom query point. For more information on the explainer object, see
shapley.
Explain Global Model Predictions Using Shapley Importance Plot
Use the Shapley values of predictors for a set of query points to interpret which predictors have the largest (or smallest) average impact on model output magnitude. For regression models, predictions are response values. The Shapley value of a predictor for a query point explains the deviation of the prediction for the query point from the average prediction, due to the predictor. The sign of the Shapley value indicates the direction of this deviation, and the absolute value indicates its magnitude. The mean of the absolute Shapley values for a predictor over all query points, therefore, provides a measure of the predictor's importance for model predictions.
After you train a model in Regression Learner, select the model in the
Models pane. On the Explain tab, in
the Global Importance section, click Shapley
Importance. The app opens a new tab and computes the Shapley values
for a set of query points using the shapley
function. When computing Shapley values, the app uses the full model, trained on the
training data set (which includes validation data, but excludes test data). When the
computation is complete, the app displays a bar chart of the mean absolute Shapley
values for the top predictors, sorted from highest to lowest. Point to a bar to
display information about the mean absolute Shapley value.
Note
Regression Learner does not support global Shapley explanations for models trained after applying principal component analysis (PCA).
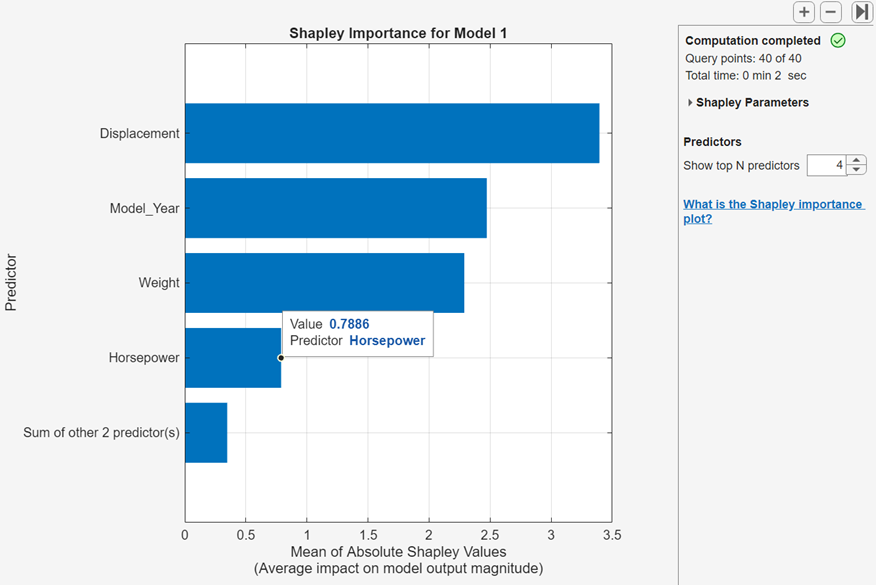
If the trained model includes many predictors, you can choose to display only the most important predictors in the bar chart. To the right of the Shapley plot, enter a value in the Show top N predictors box to display the N predictors with the largest mean absolute Shapley values. If the data set contains more than N predictors, the plot includes a bar that shows the sum of the other predictor values.
To view a table of Shapley computation parameters, click Shapley Parameters to the right of the Shapley plot. You can edit these parameters by clicking Edit. For more information, see Adjust Global Shapley Plot Parameters.
Export Shapley Results
After computing Shapley values, you can export your results by using options in the Export section on the Explain tab.
To export the Shapley plot to a figure, click Export Plot and select Export Plot to Figure.
To export the Shapley plot results to the workspace, click Export Plot and select Export Plot Data. In the dialog box, edit the name of the exported variable, if necessary, and click OK. The app creates a structure array that contains the Shapley explainer object. For more information on the explainer object, see
shapley.
Explain Global Model Predictions Using Shapley Summary Plot
Use the Shapley values of predictors for a set of query points to interpret the impact of individual predictors on model predictions. For regression models, predictions are response values. The Shapley value of a predictor for a query point explains the deviation of the prediction for the query point from the average prediction, due to the predictor. The sign of the Shapley value indicates the direction of this deviation, and the absolute value indicates its magnitude. Therefore, Shapley values near zero indicate that the predictor has a minimal impact on the model predictions for that query point.
After you train a model in Regression Learner, select the model in the
Models pane. On the Explain tab, in
the Global Importance section, click Shapley
Summary. The app opens a new tab and computes the Shapley values for
a set of query points using the shapley
function. When computing Shapley values, the app uses the full model, trained on the
training data set (which includes validation data, but excludes test data). When the
computation is complete, the app calls the swarmchart function and displays a swarm chart of the Shapley values
for the top predictors, sorted from highest to lowest mean absolute Shapley value.
Point to a query point to display its Shapley value, predictor name, predictor
value, and data set index.
Note
Regression Learner does not support global Shapley explanations for models trained after applying principal component analysis (PCA).

You can change Shapley plot and computation options using the menus located to the right of the plot.
The app colors each query point according to its predictor value, from low to high. You can select a different colormap from the Colormap list. The example above uses the default
Parulacolormap and displays a Shapley summary plot for a model trained using thecarbigdata set withMPG(miles per gallon) as the response variable. The query points forDisplacementwith positive Shapley values have dark blue colors, indicating that they have relatively lowDisplacementvalues. Their high positive Shapley values suggest that if an observation has a lowDisplacementvalue, it is likely to have a larger predictedMPGvalue than average. To explore the Shapley values for specific predictors in more detail, see Explain Global Model Predictions Using Shapley Dependence Plot.If the trained model includes many predictors, you can choose to display only the most important predictors. To the right of the Shapley plot, enter a value in the Show top N predictors box to display the N predictors with the largest mean absolute Shapley values.
By default, the app plots each predictor Shapley value with a random vertical offset (jitter) whose magnitude depends on the density of query points along the x-axis for that predictor. To apply a uniform random vertical jitter to the Shapley values, select
randomlyfrom the Jitter points list.To display a box chart instead of a swarm chart, click Box chart under Style. You can add a random vertical offset to the outlier points by selecting
truein the Jitter outliers list. For more information, seeboxchart.To view a table of Shapley computation parameters, click Shapley Parameters. You can edit these parameters by clicking Edit. For more information, see Adjust Global Shapley Plot Parameters.
Export Shapley Results
After computing Shapley values, you can export your results by using options in the Export section on the Explain tab.
To export the Shapley plot to a figure, click Export Plot and select Export Plot to Figure.
To export the Shapley plot results to the workspace, click Export Plot and select Export Plot Data. In the dialog box, edit the name of the exported variable, if necessary, and click OK. The app creates a structure array that contains the Shapley explainer object. For more information on the explainer object, see
shapley.
Explain Global Model Predictions Using Shapley Dependence Plot
Use the Shapley values of predictors for a set of query points to interpret the impact of individual predictors on model predictions. For regression models, predictions are response values. The Shapley value of a predictor for a query point explains the deviation of the prediction for the query point from the average prediction, due to the predictor. The sign of the Shapley value indicates the direction of this deviation, and the absolute value indicates its magnitude. Therefore, Shapley values near zero, indicate that the predictor has a minimal impact on the model predictions for that query point.
After you train a model in Regression Learner, select the model in the
Models pane. On the Explain tab, in
the Global Dependence section, click Shapley
Dependence. The app opens a new tab and computes the Shapley values
for a set of query points using the shapley
function. When computing Shapley values, the app uses the full model, trained on the
training data set (which includes validation data, but excludes test data). When the
computation is complete, the app calls the plotDependence function and displays a scatter plot (or box chart if
the predictor values are categorical) of the Shapley values versus predictor values.
By default, the plot shows the first predictor in the data set. Point to a query
point of a predictor to display its values.
Note
Regression Learner does not support global Shapley explanations for models trained after applying principal component analysis (PCA).

You can change Shapley plot and computation options using the menus located to the right of the plot.
You can color the query points according to the relative value of a specific predictor by selecting an entry in the Color list under Predictors. Select a colormap from the Colormap list, and restrict the colormap to a specific range by entering values in the Minimum and Maximum boxes under Colormap Range. The example above uses the default
Parulacolormap and displays a Shapley dependence plot for a model trained using thecarbigdata set withMPG(miles per gallon) as the response variable. The query points are colored according toWeight. The plot shows a strong negative correlation between the Shapley values and predictor values forDisplacement. The cluster of blue points with high positive Shapley values suggests that if an observation has a lowDisplacementvalue and a lowWeightvalue, it is likely to have a larger predictedMPGvalue.To display a different predictor, select an entry in the X-axis list under Predictors.
To view a table of Shapley computation parameters, click Shapley Parameters. You can edit these parameters by clicking Edit. For more information, see Adjust Global Shapley Plot Parameters.
Export Shapley Results
After computing Shapley values, you can export your results by using options in the Export section on the Explain tab.
To export the Shapley plot to a figure, click Export Plot and select Export Plot to Figure.
To export the Shapley plot results to the workspace, click Export Plot and select Export Plot Data. In the dialog box, edit the name of the exported variable, if necessary, and click OK. The app creates a structure array that contains the Shapley explainer object. For more information on the explainer object, see
shapley.
Adjust Global Shapley Plot Parameters
To adjust Shapley options for the global Shapley plots, click Shapley Parameters to the right of the Shapley plot and click Edit. In the Shapley Parameters dialog box, you can set these options under Query points:
Query data set — Specify the data set from which to draw the query points. If you have not loaded a test data set, the app draws query points from the training data. Otherwise, you can choose to draw query points from the training data, the test data, or all data (training and test).
Num query points — Specify the number of query points to randomly select from the query data set. For faster computations, consider using a smaller number of query points.
You can set these additional options under Advanced settings:
Shapley method — Specify the algorithm to use when computing Shapley values. The
Interventional (auto)option computes Shapley values with an interventional value function, and uses the Kernel SHAP algorithm. TheConditionaloption uses the extension to the Kernel SHAP algorithm with a conditional value function. For more information, seeMethod.Shapley observation samples — Specify the number of observations sampled from the training data set to use for Shapley value computations. (Recall that the training data set contains the data used to train the full model and does not include test set data.) For more information, see
NumObservationsToSample.Tip
When the training data set has over 1000 observations, the Shapley value computations might be slow. For faster computations, consider using a smaller number of observation samples.
Maximum predictor subsets — Select the maximum number of predictor subsets to use for Shapley value computations. For more information, see
MaxNumSubsets.
To apply the settings and recompute the Shapley values, click Save and Recompute. The app updates the Shapley importance, Shapley summary, and Shapley dependence plots for the currently selected model. For more information on the algorithms used to compute Shapley values, see Shapley Values for Machine Learning Model.
Interpret Model Using Partial Dependence Plots
Partial dependence plots (PDPs) allow you to visualize the marginal effect of each predictor on the predicted response of a trained regression model. After you train a model in Regression Learner, you can view a partial dependence plot for the model. On the Explain tab, in the Global Dependence section, click Partial Dependence. When computing partial dependence values, the app uses the full model, trained on the training data set (which includes validation data, but excludes test data).
To investigate your results, use the controls on the right.
Under Data, choose whether to plot results using Training set data or Test set data. The training set refers to the data used to train the full model and does not include any test set data.
Under Feature, choose the feature to plot using the X list. The plotted line corresponds to the average predicted response across the predictor values. The x-axis tick marks in the plot correspond to the unique predictor values in the selected data set.
If you use PCA to train a model, you can select principal components from the X list.
Zoom in and out, or pan across the plot. To enable zooming or panning, place the mouse over the PDP and click the corresponding button on the toolbar that appears above the top right of the plot.

For an example, see Use Partial Dependence Plots to Interpret Regression Models Trained in Regression Learner App. For more
information on partial dependence plots, see plotPartialDependence.
To export PDPs you create in the app to figures, see Export Plots in Regression Learner App.
See Also
lime | permutationImportance | shapley | plotPartialDependence | partialDependence