scatterhist
Scatter plot with marginal histograms
Description
scatterhist( creates
the plot using additional options specified by one or more name-value
pair arguments. For example, you can specify a grouping variable or
change the display options.x,y,Name,Value)
Examples
Load the sample data. Create data vector x from the first column of the data matrix, which contains sepal length measurements from iris flowers. Create data vector y from the second column of the data matrix, which contains sepal width measurements from the same flowers.
load fisheriris
x = meas(:,1);
y = meas(:,2);Create a scatter plot and two marginal histograms to visualize the relationship between sepal length and sepal width.
scatterhist(x,y)

Display a data tip for a bin in a histogram. A data tip appears when you hover over a bin in a histogram.
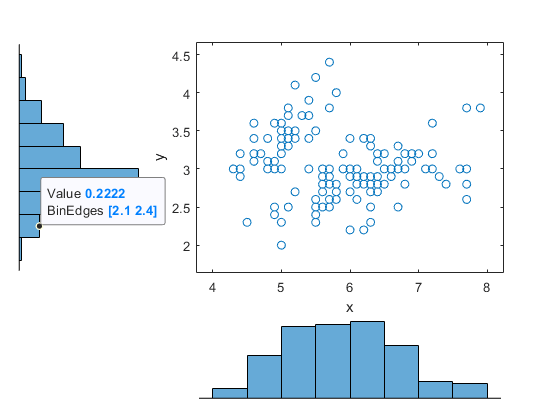
The data tip displays the probability density function estimate of the selected bin and the lower and upper values for the bin edges.
Load the sample data. Create data vector x from the first column of the data matrix, which contains sepal length measurements from three species of iris flowers. Create data vector y from the second column of the data matrix, which contains sepal width measurements from the same flowers.
load fisheriris.mat;
x = meas(:,1);
y = meas(:,2);Create a scatter plot and six kernel density plots to visualize the relationship between sepal length and sepal width, grouped by species.
scatterhist(x,y,'Group',species,'Kernel','on')
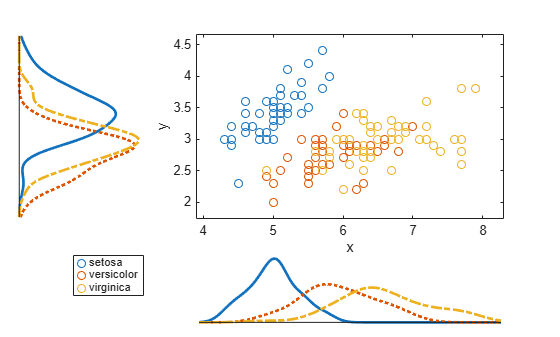
The plot shows that the relationship between sepal length and width varies depending on the flower species.
Load the sample data. Create data vector x from the first column of the data matrix, which contains sepal length measurements from three different species of iris flowers. Create data vector y from the second column of the data matrix, which contains sepal width measurements from the same flowers.
load fisheriris.mat;
x = meas(:,1);
y = meas(:,2);Create a scatter plot and six kernel density plots to visualize the relationship between sepal length and sepal width as measured on three species of iris flowers, grouped by species. Customize the appearance of the plots.
scatterhist(x,y,'Group',species,'Kernel','on','Location','SouthEast',... 'Direction','out','Color','kbr','LineStyle',{'-','-.',':'},... 'LineWidth',[2,2,2],'Marker','+od','MarkerSize',[4,5,6]);
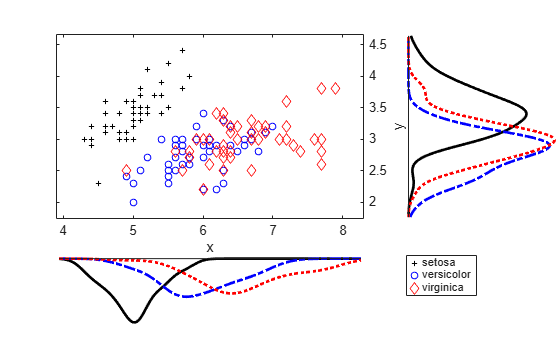
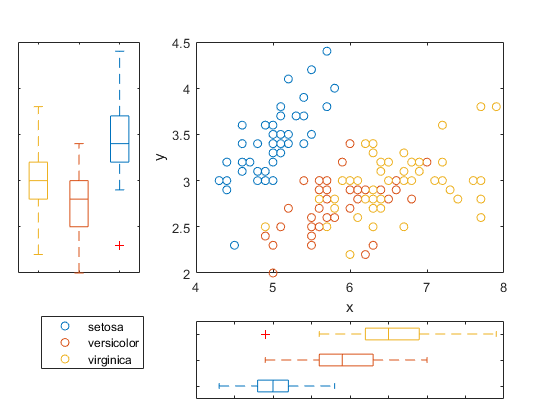
Load the sample data. Create data vector x from the first column of the data matrix, which contains sepal length measurements from three species of iris flowers. Create data vector y from the second column of the data matrix, which contains sepal width measurements from the same flowers.
load fisheriris.mat;
x = meas(:,1);
y = meas(:,2);
Use axis handles to replace the marginal histograms with box plots.
h = scatterhist(x,y,'Group',species); hold on; clr = get(h(1),'colororder'); boxplot(h(2),x,species,'orientation','horizontal',... 'label',{'','',''},'color',clr); boxplot(h(3),y,species,'orientation','horizontal',... 'label', {'','',''},'color',clr); set(h(2:3),'XTickLabel',''); view(h(3),[270,90]); % Rotate the Y plot axis(h(1),'auto'); % Sync axes hold off;
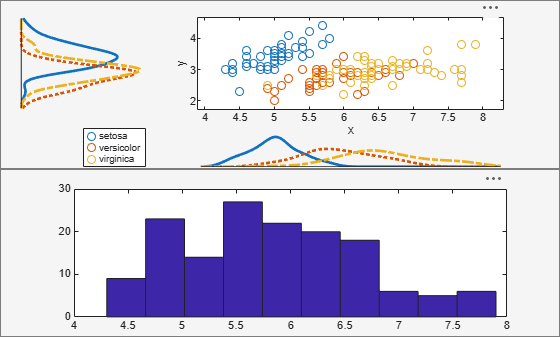
Load the sample data. Create data vector x from the first column of the data matrix, which contains sepal length measurements from iris flowers. Create data vector y from the second column of the data matrix, which contains sepal width measurements from the same flowers.
load fisheriris
x = meas(:,1);
y = meas(:,2);Create a new figure and define two uipanel objects to divide the figure into two parts. In the upper half of the figure, plot the sample data using scatterhist. Include marginal kernel density plots grouped by species. In the lower half of the figure, plot a histogram of the sepal length measurements contained in x.
figure hp1 = uipanel('position',[0 .5 1 .5]); hp2 = uipanel('position',[0 0 1 .5]); scatterhist(x,y,'Group',species,'Kernel','on','Parent',hp1); axes('Parent',hp2); hist(x);
Input Arguments
Name-Value Arguments
Output Arguments
Alternative Functionality
Alternatively, you can create a ScatterHistogramChart object by
using the scatterhistogram function.
Explore the data interactively in the object by panning, zooming, and using data tips. Unlike the
scatterhistfunction,scatterhistogramupdates the marginal histograms based on the data within the current scatter plot limits.Control the appearance and behavior of the scatter histogram chart by changing the ScatterHistogramChart Properties.