predict
Predict responses for new observations from kernel incremental learning model
Since R2022a
Description
Examples
Create an incremental learning model by converting a traditionally trained kernel model, and predict responses using both models.
Load the 2015 NYC housing data set. For more details on the data, see NYC Open Data.
load NYCHousing2015Extract the response variable SALEPRICE from the table. For numerical stability, scale SALEPRICE by 1e6.
Y = NYCHousing2015.SALEPRICE/1e6; NYCHousing2015.SALEPRICE = [];
To reduce computational cost for this example, remove the NEIGHBORHOOD column, which contains a categorical variable with 254 categories.
NYCHousing2015.NEIGHBORHOOD = [];
Create dummy variable matrices from the other categorical predictors.
catvars = ["BOROUGH","BUILDINGCLASSCATEGORY"]; dumvarstbl = varfun(@(x)dummyvar(categorical(x)),NYCHousing2015, ... InputVariables=catvars); dumvarmat = table2array(dumvarstbl); NYCHousing2015(:,catvars) = [];
Treat all other numeric variables in the table as predictors of sales price. Concatenate the matrix of dummy variables to the rest of the predictor data.
idxnum = varfun(@isnumeric,NYCHousing2015,OutputFormat="uniform");
X = [dumvarmat NYCHousing2015{:,idxnum}];Fit a kernel regression model to the entire data set.
Mdl = fitrkernel(X,Y)
Mdl =
RegressionKernel
ResponseName: 'Y'
Learner: 'svm'
NumExpansionDimensions: 2048
KernelScale: 1
Lambda: 1.0935e-05
BoxConstraint: 1
Epsilon: 0.0549
Properties, Methods
Mdl is a RegressionKernel model object representing a traditionally trained kernel regression model.
Convert the traditionally trained kernel regression model to a model for incremental learning.
IncrementalMdl = incrementalLearner(Mdl)
IncrementalMdl =
incrementalRegressionKernel
IsWarm: 1
Metrics: [1×2 table]
ResponseTransform: 'none'
NumExpansionDimensions: 2048
KernelScale: 1
Properties, Methods
IncrementalMdl is an incrementalRegressionKernel model object prepared for incremental learning.
The incrementalLearner function initializes the incremental learner by passing model parameters to it, along with other information Mdl extracted from the training data. IncrementalMdl is warm (IsWarm is 1), which means that incremental learning functions can start tracking performance metrics.
An incremental learner created from converting a traditionally trained model can generate predictions without further processing.
Predict sales prices for all observations using both models.
ttyfit = predict(Mdl,X); ilyfit = predict(IncrementalMdl,X); compareyfit = norm(ttyfit - ilyfit)
compareyfit = 0
The difference between the fitted values generated by the models is 0.
To compute posterior class probabilities, specify a logistic regression incremental learner.
Load the human activity data set. Randomly shuffle the data.
load humanactivity n = numel(actid); rng(10) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
For details on the data set, enter Description at the command line.
Responses can be one of five classes: Sitting, Standing, Walking, Running, or Dancing. Dichotomize the response by identifying whether the subject is moving (actid > 2).
Y = Y > 2;
Create an incremental logistic regression model for binary classification. Prepare it for predict by fitting the model to the first 10 observations.
Mdl = incrementalClassificationKernel(Learner="logistic");
initobs = 10;
Mdl = fit(Mdl,X(1:initobs,:),Y(1:initobs));Mdl is an incrementalClassificationKernel model. All its properties are read-only.
Simulate a data stream, and perform the following actions on each incoming chunk of 50 observations:
Call
predictto predict classification scores for the observations in the incoming chunk of data. The classification scores are posterior class probabilities for logistic regression learners.Call
rocmetricsto compute the area under the ROC curve (AUC) using the classification scores, and store the result.Call
fitto fit the model to the incoming chunk. Overwrite the previous incremental model with a new one fitted to the incoming observations.
numObsPerChunk = 50; nchunk = floor((n - initobs)/numObsPerChunk); auc = zeros(nchunk,1); % Incremental learning for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1 + initobs); iend = min(n,numObsPerChunk*j + initobs); idx = ibegin:iend; [~,posteriorProb] = predict(Mdl,X(idx,:)); mdlROC = rocmetrics(Y(idx),posteriorProb,Mdl.ClassNames); auc(j) = mdlROC.AUC(2); Mdl = fit(Mdl,X(idx,:),Y(idx)); end
Mdl is an incrementalClassificationKernel model object trained on all the data in the stream.
Plot the AUC for the incoming chunks of data.
plot(auc) xlim([0 nchunk]) ylabel("AUC") xlabel("Iteration")
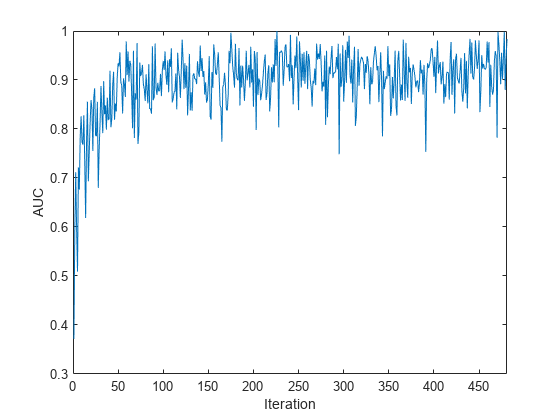
The plot suggests that the classifier predicts moving subjects well during incremental learning.