fitdist
Fit probability distribution object to data
Syntax
Description
pd = fitdist(x,distname,Name,Value)
[ creates
probability distribution objects by fitting the distribution specified
by pdca,gn,gl]
= fitdist(x,distname,'By',groupvar)distname to the data in x based
on the grouping variable groupvar. It returns
a cell array of fitted probability distribution objects, pdca,
a cell array of group labels, gn, and a cell
array of grouping variable levels, gl.
Examples
Fit a normal distribution to sample data, and examine the fit by using a histogram and a quantile-quantile plot.
Load patient weights from the data file patients.mat.
load patients
x = Weight;Create a normal distribution object by fitting it to the data.
pd = fitdist(x,'Normal')pd =
NormalDistribution
Normal distribution
mu = 154 [148.728, 159.272]
sigma = 26.5714 [23.3299, 30.8674]
The distribution object display includes the parameter estimates for the mean (mu) and standard deviation (sigma), and the 95% confidence intervals for the parameters.
You can use the object functions of pd to evaluate the distribution and generate random numbers. Display the supported object functions.
methods(pd)
Methods for class prob.NormalDistribution: cdf gather icdf iqr mean median negloglik paramci pdf plot proflik random std truncate var
For example, obtain the 95% confidence intervals by using the paramci function.
ci95 = paramci(pd)
ci95 = 2×2
148.7277 23.3299
159.2723 30.8674
Specify the significance level (Alpha) to obtain confidence intervals with a different confidence level. Compute the 99% confidence intervals.
ci99 = paramci(pd,'Alpha',.01)ci99 = 2×2
147.0213 22.4257
160.9787 32.4182
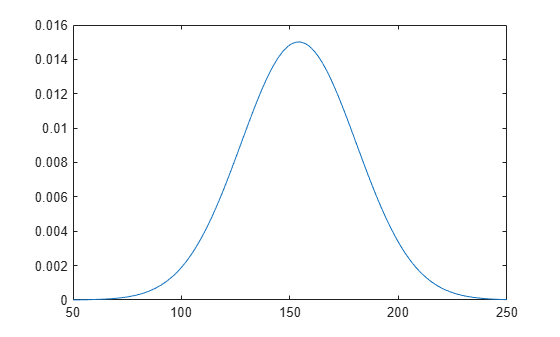
Evaluate and plot the pdf values of the distribution.
x_values = 50:1:250; y = pdf(pd,x_values); plot(x_values,y)
Create a histogram with the normal distribution fit by using the histfit function. histfit uses fitdist to fit a distribution to data.
histfit(x)
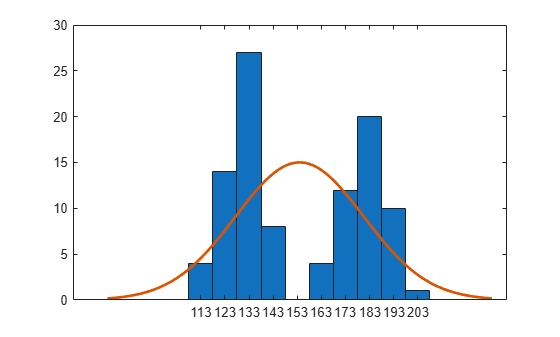
The histogram shows that the data has two modes, and that the mode of the normal distribution fit is between those two modes.
Use qqplot to create a quantile-quantile plot of the quantiles of the sample data x versus the theoretical quantile values of the fitted distribution.
qqplot(x,pd)
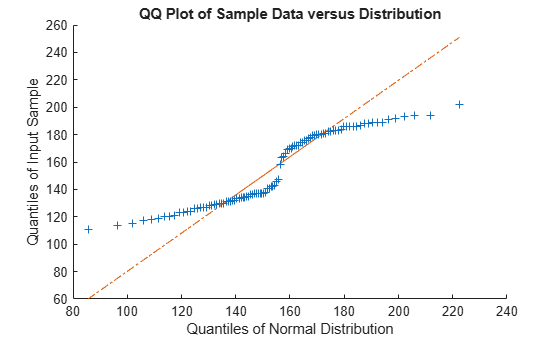
The plot is not a straight line, suggesting that the data does not follow a normal distribution.
Load patient weights from the data file patients.mat.
load patients
x = Weight;Create a kernel distribution object by fitting it to the data. Use the Epanechnikov kernel function.
pd = fitdist(x,'Kernel','Kernel','epanechnikov')
pd =
KernelDistribution
Kernel = epanechnikov
Bandwidth = 14.3792
Support = unbounded
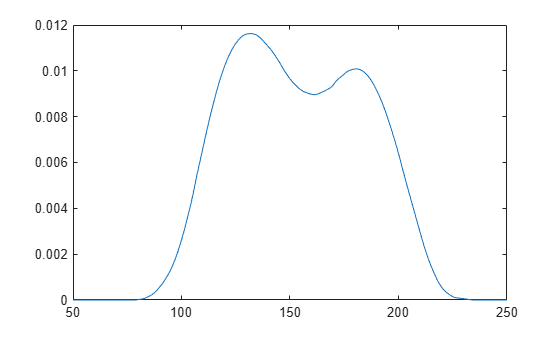
Plot the pdf of the distribution.
x_values = 50:1:250; y = pdf(pd,x_values); plot(x_values,y)
Load patient weights and genders from the data file patients.mat.
load patients
x = Weight;Create normal distribution objects by fitting them to the data, grouped by patient gender.
[pdca,gn,gl] = fitdist(x,'Normal','By',Gender)
pdca=1×2 cell array
{1×1 prob.NormalDistribution} {1×1 prob.NormalDistribution}
gn = 2×1 cell
{'Male' }
{'Female'}
gl = 2×1 cell
{'Male' }
{'Female'}
The cell array pdca contains two probability distribution objects, one for each gender group. The cell array gn contains two group labels. The cell array gl contains two group levels.
View each distribution in the cell array pdca to compare the mean, mu, and the standard deviation, sigma, grouped by patient gender.
female = pdca{1} % Distribution for femalesfemale =
NormalDistribution
Normal distribution
mu = 180.532 [177.833, 183.231]
sigma = 9.19322 [7.63933, 11.5466]
male = pdca{2} % Distribution for malesmale =
NormalDistribution
Normal distribution
mu = 130.472 [128.183, 132.76]
sigma = 8.30339 [6.96947, 10.2736]
Compute the pdf of each distribution.
x_values = 50:1:250; femalepdf = pdf(female,x_values); malepdf = pdf(male,x_values);
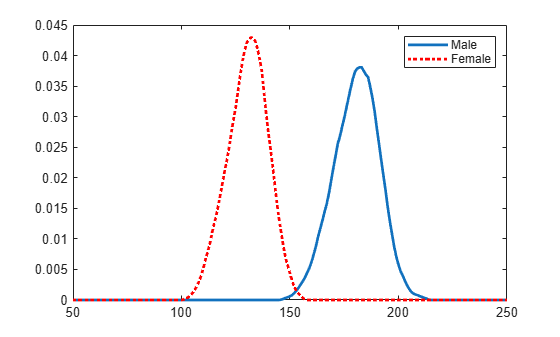
Plot the pdfs for a visual comparison of weight distribution by gender.
figure plot(x_values,femalepdf,'LineWidth',2) hold on plot(x_values,malepdf,'Color','r','LineStyle',':','LineWidth',2) legend(gn,'Location','NorthEast') hold off

Load patient weights and genders from the data file patients.mat.
load patients
x = Weight;Create kernel distribution objects by fitting them to the data, grouped by patient gender. Use a triangular kernel function.
[pdca,gn,gl] = fitdist(x,'Kernel','By',Gender,'Kernel','triangle');
View each distribution in the cell array pdca to see the kernel distributions for each gender.
female = pdca{1} % Distribution for femalesfemale =
KernelDistribution
Kernel = triangle
Bandwidth = 5.08961
Support = unbounded
male = pdca{2} % Distribution for malesmale =
KernelDistribution
Kernel = triangle
Bandwidth = 4.25894
Support = unbounded
Compute the pdf of each distribution.
x_values = 50:1:250; femalepdf = pdf(female,x_values); malepdf = pdf(male,x_values);
Plot the pdfs for a visual comparison of weight distribution by gender.
figure plot(x_values,femalepdf,'LineWidth',2) hold on plot(x_values,malepdf,'Color','r','LineStyle',':','LineWidth',2) legend(gn,'Location','NorthEast') hold off
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
The fitdist function fits most distributions
using maximum likelihood estimation. Two exceptions are the normal
and lognormal distributions with uncensored data.
For the uncensored normal distribution, the estimated value of the sigma parameter is the square root of the unbiased estimate of the variance.
For the uncensored lognormal distribution, the estimated value of the sigma parameter is the square root of the unbiased estimate of the variance of the log of the data.
Alternative Functionality
The Distribution Fitter app opens a graphical user interface for you to import data from the workspace and interactively fit a probability distribution to that data. You can then save the distribution to the workspace as a probability distribution object. Open the Distribution Fitter app using
distributionFitterat the command line, or click Distribution Fitter on the Apps tab.To fit a distribution to left-censored, double-censored, or interval-censored data, use
mle. You can find the maximum likelihood estimates by using themlefunction, and create a probability distribution object by using themakedistfunction. For an example, see Find MLEs for Double-Censored Data.
References
[1] Johnson, N. L., S. Kotz, and N. Balakrishnan. Continuous Univariate Distributions. Vol. 1, Hoboken, NJ: Wiley-Interscience, 1993.
[2] Johnson, N. L., S. Kotz, and N. Balakrishnan. Continuous Univariate Distributions. Vol. 2, Hoboken, NJ: Wiley-Interscience, 1994.
[3] Bowman, A. W., and A. Azzalini. Applied Smoothing Techniques for Data Analysis. New York: Oxford University Press, 1997.