fairnessMetrics
Description
fairnessMetrics computes fairness metrics (bias and group
metrics) for a data set or binary classification model with respect to sensitive attributes.
The data-level evaluation examines binary, true labels of the data. The model-level evaluation
examines the predicted labels returned by one or more binary classification models, using both
true labels and predicted labels.
Bias metrics measure differences across groups, and group metrics contain information within the group. You can use the metrics to determine if your data or models contain bias toward a group within each sensitive attribute.
After creating a fairnessMetrics object, use the report function to
generate a fairness metrics report or use the plot function to
create a bar graph of the metrics.
Creation
Syntax
Description
metricsResults = fairnessMetrics(SensitiveAttributes,Y)Y with respect to the sensitive attributes in the
SensitiveAttributes matrix. The fairnessMetrics
function returns the fairnessMetrics object
metricsResults, which stores bias metrics and group metrics in the
BiasMetrics and
GroupMetrics
properties, respectively.
metricsResults = fairnessMetrics(Tbl,ResponseName)Tbl. The input argument ResponseName
specifies the name of the variable in Tbl that contains the class
labels.
metricsResults = fairnessMetrics(___,SensitiveAttributeNames=sensitiveAttributeNames)Tbl (whose names correspond to
sensitiveAttributeNames) as sensitive attributes, or assigns names
to the sensitive attributes in sensitiveAttributeNames. You can
specify this argument in addition to any of the input argument combinations in the
previous syntaxes.
metricsResults = fairnessMetrics(___,Predictions=predictions)predictions argument.
fairnessMetrics uses both true labels and predicted labels for the
model-level evaluation.
metricsResults = fairnessMetrics(___,Name=Value)SensitiveAttributeNames="age",ReferenceGroup=30 to compute bias
metrics for each group in the age variable with respect to the
reference age group 30.
Input Arguments
Name-Value Arguments
Properties
Examples
Compute fairness metrics for true labels with respect to sensitive attributes by creating a fairnessMetrics object. Then, create a table of fairness metrics by using the report function, and plot bar graphs of the metrics by using the plot function.
Load the sample data census1994, which contains the training data adultdata and the test data adulttest. The data sets consist of demographic information from the US Census Bureau that can be used to predict whether an individual makes over $50,000 per year. Preview the first few rows of the training data set.
load census1994
head(adultdata) age workClass fnlwgt education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
___ ________________ __________ _________ _____________ _____________________ _________________ _____________ _____ ______ ____________ ____________ ______________ ______________ ______
39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
38 Private 2.1565e+05 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
53 Private 2.3472e+05 11th 7 Married-civ-spouse Handlers-cleaners Husband Black Male 0 0 40 United-States <=50K
28 Private 3.3841e+05 Bachelors 13 Married-civ-spouse Prof-specialty Wife Black Female 0 0 40 Cuba <=50K
37 Private 2.8458e+05 Masters 14 Married-civ-spouse Exec-managerial Wife White Female 0 0 40 United-States <=50K
49 Private 1.6019e+05 9th 5 Married-spouse-absent Other-service Not-in-family Black Female 0 0 16 Jamaica <=50K
52 Self-emp-not-inc 2.0964e+05 HS-grad 9 Married-civ-spouse Exec-managerial Husband White Male 0 0 45 United-States >50K
Each row contains the demographic information for one adult. The information includes sensitive attributes, such as age, marital_status, relationship, race, and sex. The third column flnwgt contains observation weights, and the last column salary shows whether a person has a salary less than or equal to $50,000 per year (<=50K) or greater than $50,000 per year (>50K).
This example evaluates the fairness of the salary variable with respect to age. Group the age variable into four bins.
ageGroups = ["Age<30","30<=Age<45","45<=Age<60","Age>=60"]; adultdata.age_group = discretize(adultdata.age, ... [min(adultdata.age) 30 45 60 max(adultdata.age)], ... categorical=ageGroups);
Plot the counts of individuals in each class (<=50K and >50K) by age.
figure gc = groupcounts(adultdata,["age_group","salary"]); bar([gc.GroupCount(1:2:end),gc.GroupCount(2:2:end)]) xticklabels(ageGroups) xlabel("Age Group") ylabel("Group Count") legend(["<=50K",">50K"]) grid on
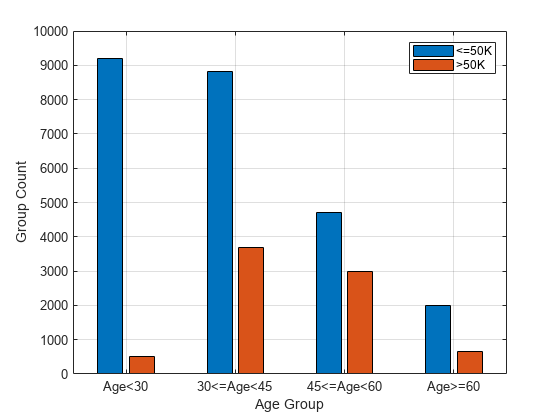
Compute fairness metrics for the salary variable with respect to the age_group variable by using fairnessMetrics.
metricsResults = fairnessMetrics(adultdata,"salary", ... SensitiveAttributeNames="age_group",Weights="fnlwgt")
metricsResults =
fairnessMetrics with properties:
SensitiveAttributeNames: 'age_group'
ReferenceGroup: '30<=Age<45'
ResponseName: 'salary'
PositiveClass: >50K
BiasMetrics: [4×4 table]
GroupMetrics: [4×4 table]
Properties, Methods
metricsResults is a fairnessMetrics object. By default, the fairnessMetrics function selects the majority group of the sensitive attribute (group with the largest number of individuals) as the reference group for the attribute. Also, the fairnessMetrics function orders the labels by using the unique function with the "sorted" option, and specifies the second class of the labels as the positive class. In this data set, the reference group of age_group is the group 30<=Age<45, and the positive class is >50K. The object stores bias metrics and group metrics in the BiasMetrics and GroupMetrics properties, respectively. Display the properties.
metricsResults.BiasMetrics
ans=4×4 table
SensitiveAttributeNames Groups StatisticalParityDifference DisparateImpact
_______________________ __________ ___________________________ _______________
age_group Age<30 -0.24365 0.17661
age_group 30<=Age<45 0 1
age_group 45<=Age<60 0.098497 1.3329
age_group Age>=60 -0.05041 0.82965
metricsResults.GroupMetrics
ans=4×4 table
SensitiveAttributeNames Groups GroupCount GroupSizeRatio
_______________________ __________ __________ ______________
age_group Age<30 9711 0.29824
age_group 30<=Age<45 12489 0.38356
age_group 45<=Age<60 7717 0.237
age_group Age>=60 2644 0.081201
According to the bias metrics, the salary variable is biased toward the age group 45 to 60 years and biased against the age group less than 30 years, compared to the reference group (30<=Age<45).
You can create a table that contains both bias metrics and group metrics by using the report function. Specify GroupMetrics as "all" to include all group metrics. You do not have to specify the BiasMetrics name-value argument because its default value is "all".
metricsTbl = report(metricsResults,GroupMetrics="all")metricsTbl=4×6 table
SensitiveAttributeNames Groups StatisticalParityDifference DisparateImpact GroupCount GroupSizeRatio
_______________________ __________ ___________________________ _______________ __________ ______________
age_group Age<30 -0.24365 0.17661 9711 0.29824
age_group 30<=Age<45 0 1 12489 0.38356
age_group 45<=Age<60 0.098497 1.3329 7717 0.237
age_group Age>=60 -0.05041 0.82965 2644 0.081201
Visualize the bias metrics by using the plot function.
figure t = tiledlayout(2,1); nexttile plot(metricsResults,"spd") xlabel("") ylabel("") nexttile plot(metricsResults,"di") xlabel("") ylabel("") xlabel(t,"Fairness Metric Value") ylabel(t,"Age Group")
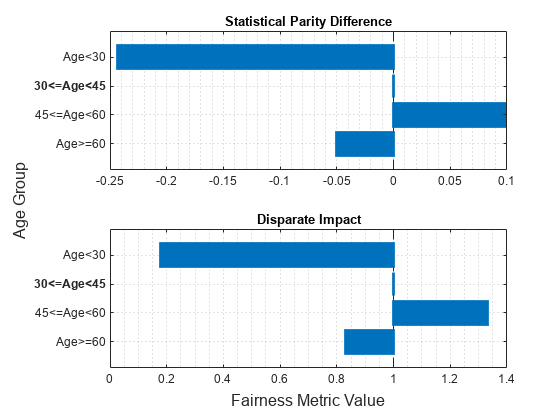
The vertical line in each plot ( for statistical parity difference and for disparate impact) indicates the metric value for the reference group. If the labels do not have a bias for a target group compared to the reference group, the metric value for the target group is the same as the metric value for the reference group.
Compute fairness metrics for predicted labels with respect to sensitive attributes by creating a fairnessMetrics object. Then, create a table of fairness metrics by using the report function, and plot bar graphs of the metrics by using the plot function.
Load the sample data census1994, which contains the training data adultdata and the test data adulttest. The data sets consist of demographic information from the US Census Bureau that can be used to predict whether an individual makes over $50,000 per year. Preview the first few rows of the training data set.
load census1994
head(adultdata) age workClass fnlwgt education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
___ ________________ __________ _________ _____________ _____________________ _________________ _____________ _____ ______ ____________ ____________ ______________ ______________ ______
39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
38 Private 2.1565e+05 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
53 Private 2.3472e+05 11th 7 Married-civ-spouse Handlers-cleaners Husband Black Male 0 0 40 United-States <=50K
28 Private 3.3841e+05 Bachelors 13 Married-civ-spouse Prof-specialty Wife Black Female 0 0 40 Cuba <=50K
37 Private 2.8458e+05 Masters 14 Married-civ-spouse Exec-managerial Wife White Female 0 0 40 United-States <=50K
49 Private 1.6019e+05 9th 5 Married-spouse-absent Other-service Not-in-family Black Female 0 0 16 Jamaica <=50K
52 Self-emp-not-inc 2.0964e+05 HS-grad 9 Married-civ-spouse Exec-managerial Husband White Male 0 0 45 United-States >50K
Each row contains the demographic information for one adult. The information includes sensitive attributes, such as age, marital_status, relationship, race, and sex. The third column flnwgt contains observation weights, and the last column salary shows whether a person has a salary less than or equal to $50,000 per year (<=50K) or greater than $50,000 per year (>50K).
Train a classification tree using the training data set adultdata. Specify the response variable, predictor variables, and observation weights by using the variable names in the adultdata table.
predictorNames = ["capital_gain","capital_loss","education", ... "education_num","hours_per_week","occupation","workClass"]; Mdl = fitctree(adultdata,"salary", ... PredictorNames=predictorNames,Weights="fnlwgt");
Predict the test sample labels by using the trained tree Mdl.
labels = predict(Mdl,adulttest);
This example evaluates the fairness of the predicted labels with respect to age and marital status. Group the age variable into four bins.
ageGroups = ["Age<30","30<=Age<45","45<=Age<60","Age>=60"]; adulttest.age_group = discretize(adulttest.age, ... [min(adulttest.age) 30 45 60 max(adulttest.age)], ... categorical=ageGroups);
Plot the counts of individuals in each predicted class (<=50K and >50K) by age.
figure
gs_age = groupcounts({adulttest.age_group,labels});
b_age = bar([gs_age(1:2:end),gs_age(2:2:end)]);
xticklabels(ageGroups)
xlabel("Age Group")
ylabel("Group Count")
legend(["<=50K",">50K"])
grid minor
Plot the counts of individuals by marital status. Display the count values near the tips of the bars if the values are smaller than 100.
figure
gs_status = groupcounts({adulttest.marital_status,labels});
b_status = bar([gs_status(1:2:end),gs_status(2:2:end)]);
xticklabels(unique(adulttest.marital_status))
xlabel("Marital Status")
ylabel("Group Count")
legend(["<=50K",">50K"])
grid minor
xtips1 = b_status(1).XEndPoints;
ytips1 = b_status(1).YEndPoints;
labels1 = string(b_status(1).YData);
ind1 = ytips1 < 100;
text(xtips1(ind1),ytips1(ind1),labels1(ind1), ...
HorizontalAlignment="center",VerticalAlignment="bottom", ...
Color=b_status(1).FaceColor)
xtips2 = b_status(2).XEndPoints;
ytips2 = b_status(2).YEndPoints;
labels2 = string(b_status(2).YData);
ind2 = ytips2 < 100;
text(xtips2(ind2),ytips2(ind2),labels2(ind2), ...
HorizontalAlignment="center",VerticalAlignment="bottom", ...
Color=b_status(2).FaceColor)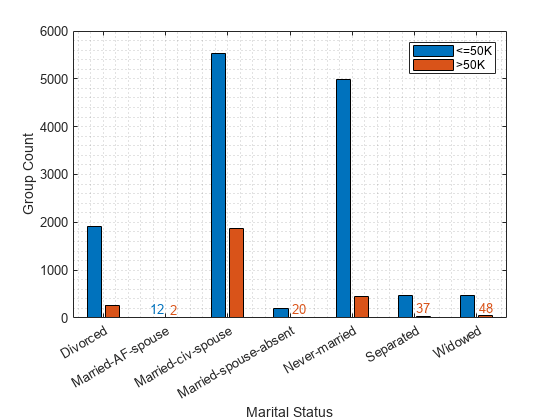
Compute fairness metrics for the predictions (labels) with respect to the age_group and marital_status variables by using fairnessMetrics.
metricsResults = fairnessMetrics(adulttest,"salary", ... SensitiveAttributeNames=["age_group","marital_status"], ... Predictions=labels,Weights="fnlwgt")
metricsResults =
fairnessMetrics with properties:
SensitiveAttributeNames: {'age_group' 'marital_status'}
ReferenceGroup: {'30<=Age<45' 'Married-civ-spouse'}
ResponseName: 'salary'
PositiveClass: >50K
BiasMetrics: [11×7 table]
GroupMetrics: [11×20 table]
ModelNames: 'Model1'
Properties, Methods
metricsResults is a fairnessMetrics object. By default, the fairnessMetrics function selects the majority group of each sensitive attribute (group with the largest number of individuals) as the reference group for the attribute. Also, the fairnessMetrics function orders the labels by using the unique function with the "sorted" option, and specifies the second class of the labels as the positive class. In this data set, the reference groups of age_group and marital_status are the groups 30<=Age<45 and Married-civ-spouse, respectively, and the positive class is >50K. The object stores bias metrics and group metrics in the BiasMetrics and GroupMetrics properties, respectively.
Create a table with fairness metrics by using the report function. Specify BiasMetrics as ["eod","aaod"] to include the equal opportunity difference (EOD) and average absolute odds difference (AAOD) metrics in the report table. The fairnessMetrics function computes the two metrics by using the true positive rates (TPR) and false positive rates (FPR). Specify GroupMetrics as ["tpr","fpr"] to include TPR and FPR values in the table.
metricsTbl = report(metricsResults, ... BiasMetrics=["eod","aaod"],GroupMetrics=["tpr","fpr"])
metricsTbl=11×7 table
ModelNames SensitiveAttributeNames Groups EqualOpportunityDifference AverageAbsoluteOddsDifference TruePositiveRate FalsePositiveRate
__________ _______________________ _____________________ __________________________ _____________________________ ________________ _________________
Model1 age_group Age<30 -0.041319 0.044114 0.41333 0.041709
Model1 age_group 30<=Age<45 0 0 0.45465 0.088618
Model1 age_group 45<=Age<60 0.061495 0.031809 0.51614 0.086495
Model1 age_group Age>=60 0.0060387 0.011955 0.46069 0.070746
Model1 marital_status Divorced 0.078541 0.043643 0.54263 0.075653
Model1 marital_status Married-AF-spouse 0.073166 0.078782 0.53726 0
Model1 marital_status Married-civ-spouse 0 0 0.46409 0.084398
Model1 marital_status Married-spouse-absent -0.067098 0.048093 0.39699 0.055311
Model1 marital_status Never-married 0.0886 0.057557 0.55269 0.057883
Model1 marital_status Separated 0.027256 0.026751 0.49135 0.058151
Model1 marital_status Widowed 0.12442 0.080073 0.58851 0.048675
Plot the EOD and AAOD values for the sensitive attribute age_group. Because age_group is the first element in the SensitiveAttributeNames property of metricsResults, it is the default value for the property. Therefore, you do not have to specify the SensitiveAttributeName argument of the plot function.
figure t = tiledlayout(1,2); nexttile plot(metricsResults,"eod") title("EOD") xlabel("") ylabel("") nexttile plot(metricsResults,"aaod") title("AAOD") xlabel("") ylabel("") yticklabels("") xlabel(t,"Fairness Metric Value") ylabel(t,"Age Group")
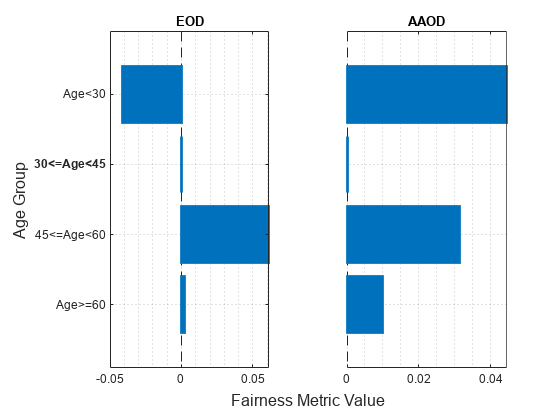
The vertical line at indicates the metric value for the reference group (30<=Age<45). If the labels do not have a bias for a target group compared to the reference group, the metric value for the target group is the same as the metric value for the reference group. According to the EOD values (differences in TPR), the predictions for the salary variable are most biased toward the group 45<=Age<60 compared to the reference group. According to the AAOD values (averaged differences in TPR and FPR), the predictions are most biased toward the group Age<30.
Plot the EOD and AAOD values for the sensitive attribute marital_status by specifying the SensitiveAttributeName argument of the plot function as marital_status.
figure t = tiledlayout(1,2); nexttile plot(metricsResults,"eod",SensitiveAttributeName="marital_status") title("EOD") xlabel("") ylabel("") nexttile plot(metricsResults,"aaod",SensitiveAttributeName="marital_status") title("AAOD") xlabel("") ylabel("") yticklabels("") xlabel(t,"Fairness Metric Value") ylabel(t,"Marital Status")
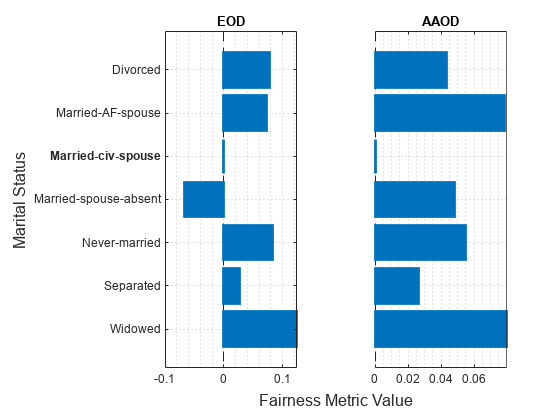
The vertical line at indicates the metric value for the reference group (Married-civ-spouse). According to the EOD values, the predictions for the salary variable are most biased toward the group Widowed compared to the reference group. According to the AAOD values, the predictions are similarly biased toward the groups Widowed and Married-AF-spouse.
Train two classification models, and compare the model predictions by using fairness metrics.
Read the sample file CreditRating_Historical.dat into a table. The predictor data consists of financial ratios and industry sector information for a list of corporate customers. The response variable consists of credit ratings assigned by a rating agency.
creditrating = readtable("CreditRating_Historical.dat");Because each value in the ID variable is a unique customer ID—that is, length(unique(creditrating.ID)) is equal to the number of observations in creditrating—the ID variable is a poor predictor. Remove the ID variable from the table, and convert the Industry variable to a categorical variable.
creditrating.ID = []; creditrating.Industry = categorical(creditrating.Industry);
In the Rating response variable, combine the AAA, AA, A, and BBB ratings into a category of "good" ratings, and the BB, B, and CCC ratings into a category of "poor" ratings.
Rating = categorical(creditrating.Rating); Rating = mergecats(Rating,["AAA","AA","A","BBB"],"good"); Rating = mergecats(Rating,["BB","B","CCC"],"poor"); creditrating.Rating = Rating;
Train a support vector machine (SVM) model on the creditrating data. For better results, standardize the predictors before fitting the model. Use the trained model to predict labels and compute the misclassification rate for the training data set.
predictorNames = ["WC_TA","RE_TA","EBIT_TA","MVE_BVTD","S_TA"]; SVMMdl = fitcsvm(creditrating,"Rating", ... PredictorNames=predictorNames,Standardize=true); SVMPredictions = resubPredict(SVMMdl); resubLoss(SVMMdl)
ans = 0.0872
Train a generalized additive model (GAM).
GAMMdl = fitcgam(creditrating,"Rating", ... PredictorNames=predictorNames); GAMPredictions = resubPredict(GAMMdl); resubLoss(GAMMdl)
ans = 0.0542
GAMMdl achieves better accuracy on the training data set.
Compute fairness metrics with respect to the sensitive attribute Industry by using the model predictions for both models.
predictions = [SVMPredictions,GAMPredictions]; metricsResults = fairnessMetrics(creditrating,"Rating", ... SensitiveAttributeNames="Industry",Predictions=predictions, ... ModelNames=["SVM","GAM"]);
Display the bias metrics by using the report function.
report(metricsResults)
ans=48×5 table
Metrics SensitiveAttributeNames Groups SVM GAM
___________________________ _______________________ ______ _________ __________
StatisticalParityDifference Industry 1 -0.028441 0.0058208
StatisticalParityDifference Industry 2 -0.04014 0.0063339
StatisticalParityDifference Industry 3 0 0
StatisticalParityDifference Industry 4 -0.04905 -0.0043007
StatisticalParityDifference Industry 5 -0.015615 0.0041607
StatisticalParityDifference Industry 6 -0.03818 -0.024515
StatisticalParityDifference Industry 7 -0.01514 0.007326
StatisticalParityDifference Industry 8 0.0078632 0.036581
StatisticalParityDifference Industry 9 -0.013863 0.042266
StatisticalParityDifference Industry 10 0.0090218 0.050095
StatisticalParityDifference Industry 11 -0.004188 0.001453
StatisticalParityDifference Industry 12 -0.041572 -0.028589
DisparateImpact Industry 1 0.92261 1.017
DisparateImpact Industry 2 0.89078 1.0185
DisparateImpact Industry 3 1 1
DisparateImpact Industry 4 0.86654 0.98742
⋮
Among the bias metrics, compare the equal opportunity difference (EOD) values. Create a bar graph of the EOD values by using the plot function.
b = plot(metricsResults,"eod"); b(1).FaceAlpha = 0.2; b(2).FaceAlpha = 0.2; legend(Location="southwest")
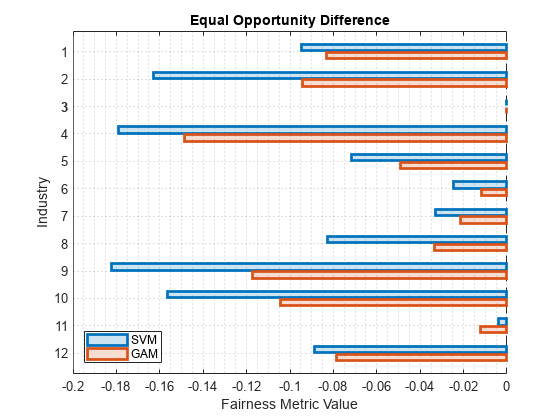
To better understand the distributions of EOD values, plot the values using box plots.
boxchart(metricsResults.BiasMetrics.EqualOpportunityDifference, ... GroupByColor=metricsResults.BiasMetrics.ModelNames) ax = gca; ax.XTick = []; ylabel("Equal Opportunity Difference") legend
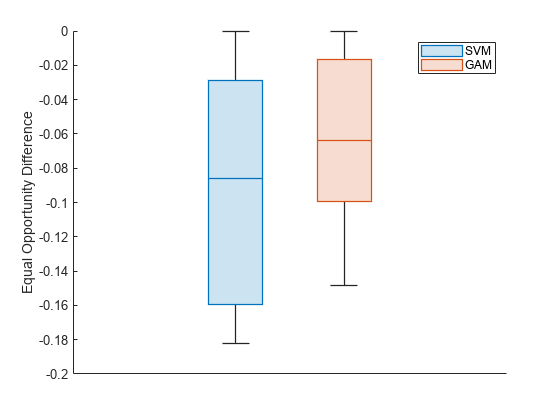
The EOD values for GAM are closer to 0 compared to the values for SVM.
More About
Algorithms
fairnessMetrics considers NaN, ''
(empty character vector), "" (empty string),
<missing>, and <undefined> values in
Tbl, Y, and
SensitiveAttributes to be missing values.
fairnessMetrics does not use observations with missing values.
References
Version History
Introduced in R2022bSee Also
Topics
- Introduction to Fairness in Binary Classification
- Explore Fairness Metrics for Credit Scoring Model (Risk Management Toolbox)