Measure and Improve GPU Performance
Measure GPU Performance
Measure Code Performance on a GPU
An important measure of the performance of your code is how long it takes to run. The best way to time code running on a GPU is to use the gputimeit function which runs a function multiple times to average out variation and compensate for overhead. The gputimeit function also ensures that all operations on the GPU are complete before recording the time.
For example, measure the time that the lu function takes to compute the LU factorization of a random matrix A of size N-by-N. To perform this measurement, create a function handle to the lu function and pass the function handle to gputimeit.
N = 1000;
A = rand(N,"gpuArray");
f = @() lu(A);
numOutputs = 2;
gputimeit(f,numOutputs)You can also time your code using tic and toc. However, to get accurate timing information for code running on a GPU, you must wait for operations to complete before calling tic and toc. To do this, you can use the wait function with a gpuDevice object as its input. For example, measure the time taken to compute the LU factorization of matrix A using tic, toc, and wait.
D = gpuDevice; wait(D) tic [L,U] = lu(A); wait(D) toc
You can view how long each part of your code takes using the MATLAB® Profiler. For more information about profiling your code, see profile and Profile Your Code to Improve Performance. The Profiler is useful for identifying performance bottlenecks in your code but cannot accurately time GPU code as it does not account for overlapping execution, which is common when you use a GPU.
Use this table to help you decide which timing method to use.
| Timing Method | Suitable Tasks | Limitations |
|---|---|---|
gputimeit | Timing individual functions |
|
tic and toc | Timing multiple lines of code or entire workflows |
|
| MATLAB Profiler | Finding performance bottlenecks | The Profiler runs each line of code independently and does not account for overlapping execution, which is common when you use a GPU. You cannot use the Profiler as a way to accurately time GPU code. |
GPU Benchmarking
Benchmark tests are useful for identifying the strengths and weaknesses of a GPU and for comparing the performance of different GPUs. Measure the performance of your GPU by using these benchmark tests:
Run the Measure GPU Memory Bandwidth and Processing Power example to obtain detailed information about your GPU, including PCI bus speed, GPU memory read/write, and peak calculation performance for double-precision matrix calculations.
Use
gpuBenchto test memory- and computation-intensive tasks in single and double precision.gpuBenchcan be downloaded from the Add-On Explorer or from the MATLAB Central File Exchange. For more information, see https://www.mathworks.com/matlabcentral/fileexchange/34080-gpubench.
Improve GPU Performance
The purpose of GPU computing in MATLAB is to speed up your code. You can achieve better performance on the GPU by implementing best practices for writing code and configuring your GPU hardware. Various methods to improve performance are discussed below, starting with the most straightforward to implement.
Use this table to help you decide which methods to use.
| Performance Improvement Method | When Should I Use This Method? | Limitations |
|---|---|---|
Use GPU Arrays – pass GPU arrays to supported functions to run your code on the GPU | Generally applicable | Your functions must support |
Profile and Improve Your MATLAB Code – profile your code to identify bottlenecks | Generally applicable | The profiler cannot be used to accurately time code running on the GPU as described in the Measure Code Performance on a GPU section. |
Vectorize Calculations – replace for-loops with matrix and vector operations | When running code that operates on vectors or matrices inside a for-loop | For more information, see Using Vectorization. |
Perform Calculations in Single Precision – reduce computation by using lower precision data | When smaller ranges of values and lower accuracy are acceptable | Some types of calculation, such as linear algebra problems, might require double-precision processing. |
Use |
|
For information about supported functions and additional limitations, see |
Use | When using a function that performs independent matrix operations on a large number of small matrices | Not all built-in MATLAB functions are supported. For information about supported functions and additional limitations, see |
Write MEX File Containing CUDA Code – access additional libraries of GPU functions | When you want access to NVIDIA® libraries or advanced CUDA features | Requires code written using the CUDA C++ framework. |
Configure Your Hardware for GPU Performance – make the best use of your hardware | Generally applicable |
|
Use GPU Arrays
If all the functions that your code uses are supported on the GPU, the only necessary modification is to transfer the input data to the GPU by calling gpuArray. For a list of MATLAB functions that support gpuArray input, see Run MATLAB Functions on a GPU.
A gpuArray object stores data in GPU memory. Because most numeric functions
in MATLAB and in many other toolboxes support gpuArray
objects, you can usually run your code on a GPU by making minimal changes. These
functions take gpuArray inputs, perform calculations on the
GPU, and return gpuArray outputs. In general, these functions
support the same arguments and data types as standard MATLAB functions that run on the CPU.
Tip
To reduce overhead, limit the number of times you transfer data between the host memory and the GPU. Create arrays directly on the GPU where possible. For more information see, Create GPU Arrays Directly. Similarly, only transfer data from the GPU back to the host memory using gather if the data needs to be displayed, saved, or used in code that does not support gpuArray objects.
Profile and Improve Your MATLAB Code
When converting MATLAB code to run on a GPU, it is best to start with MATLAB code that already performs well. Many of the guidelines for
writing code that runs well on a CPU will also improve the performance of code
that runs on a GPU. You can profile your CPU code using the MATLAB Profiler. The lines of code that take the most time on the CPU
will likely be ones that you should improve or consider moving onto the GPU
using gpuArray objects. For more information about profiling
your code, see Profile Your Code to Improve Performance.
Because the MATLAB Profiler runs each line of code independently, it does not account for overlapping execution, which is common when you use a GPU. To time whole algorithms use tic and toc or gputimeit as described in the Measure Code Performance on a GPU section.
Vectorize Calculations
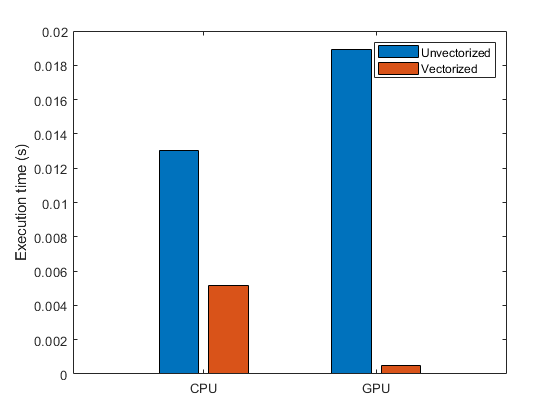
Vector, matrix, and higher-dimensional operations typically perform much better than scalar operations on a GPU because GPUs achieve high performance by calculating many results in parallel. You can achieve better performance by rewriting loops to make use of higher-dimensional operations. The process of revising loop-based, scalar-oriented code to use MATLAB matrix and vector operations is called vectorization. For information on vectorization, see Using Vectorization and Improve Performance Using a GPU and Vectorized Calculations. This plot from the Improve Performance Using a GPU and Vectorized Calculations example shows the increase in performance achieved by vectorizing a function executing on the CPU and on the GPU.
Perform Calculations in Single Precision
You can improve the performance of code running on your GPU by calculating in single precision instead of double precision, as GPUs often more have more single-precision floating-point units (FPUs) than double. In contrast, CPU computations often perform similarly for single-precision and double-precision data.
You can convert data to single precision using the single function, or you can
create single-precision gpuArray data directly by specifying
the underlying type "single" and the data type
"gpuArray" when you create data using a creation function
such as rand. For more information on
converting data to single precision and creating single-precision data directly,
see Establish Arrays on a GPU.
Typical examples of workflows suitable for single-precision computation on the GPU include image processing and machine learning. However, other types of calculation, such as linear algebra problems, typically require double-precision processing. The Deep Learning Toolbox™ performs many operations in single precision by default. For more information, see Deep Learning Precision (Deep Learning Toolbox).
The exact performance improvement depends on the GPU card and total number of cores. For an
approximate measure of the relative performance of your GPU in single precision
compared to double precision, query the SingleDoubleRatio
property of your device. This property describes the ratio of single- to
double-precision FPUs on the device.
gpu = gpuDevice; gpu.SingleDoubleRatio
Most desktop GPUs have 24, 32, or even 64 times as many single-precision floating-point units as double-precision, while some data center GPUs center GPUs (A100 and H100) have only 2 times as many.
For a comprehensive performance overview of NVIDIA GPU cards, including single- and double-precision processing power, see https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units.
Improve Performance of Element-Wise Functions
If you have an element-wise function, you can often improve its performance by calling it with
arrayfun. The
arrayfun function on the GPU turns an element-wise
MATLAB function into a custom CUDA kernel, which reduces the overhead of performing the operation.
You can often use arrayfun with a subset of your code even if
arrayfun does not support your entire code. The
performance of a wide variety of element-wise functions can be improved using
arrayfun, including functions performing many
element-wise operations within looping or branching code, and nested functions
where the nested function accesses variables declared in its parent
function.
The Improve Performance of Element-Wise MATLAB Functions on the GPU Using arrayfun example shows a basic application of arrayfun. The Using GPU arrayfun for Monte-Carlo Simulations example shows arrayfun used to improve the performance of a function executing element-wise operations within a loop. The Stencil Operations on a GPU example shows arrayfun used to call a nested function that accesses variables declared in a parent function.
Improve Performance of Operations on Small Matrices
If you have a function that performs independent matrix operations on a large number of small matrices, you can improve its performance by calling it with pagefun. You can use pagefun to perform matrix operations in parallel on the GPU instead of looping over the matrices. The Improve Performance of Small Matrix Problems on the GPU Using pagefun example shows how to improve performance using pagefun when operating on many small matrices.
Write MEX File Containing CUDA Code
While MATLAB provides an extensive library of GPU-enabled functions, you can access libraries of additional functions that do not have analogs in MATLAB. Examples include NVIDIA libraries such as the NVIDIA Performance Primitives (NPP) and cuRAND libraries. You can compile MEX files that you write in the CUDA C++ framework using the mexcuda function. You can execute the compiled MEX files in MATLAB and call functions from NVIDIA libraries. For an example that shows how to write and run MEX functions that take gpuArray input and return gpuArray output, see Run MEX Functions Containing CUDA Code.
Configure Your Hardware for GPU Performance
Because many computations require large amounts of memory and most systems use the GPU constantly for graphics, using the same GPU for computations and graphics is usually impractical.
On Windows® systems, a GPU device can be in one of three operating models:
Windows Display Driver Model (WDDM), Tesla Compute Cluster (TCC), and
Microsoft® Compute Driver Model (MCDM). To attain the best performance for
your code, set the devices that you use for computing to use the TCC or MCDM
model. To see which model your GPU device is using, inspect the
DriverModel property returned by the gpuDevice function. For more
information about switching models and which GPU devices support the TCC and
MCDM models, consult the NVIDIA documentation.
To reduce the likelihood of running out of memory on the GPU, do not use one GPU on multiple instances of MATLAB. To see which GPU devices are available and selected, use the gpuDeviceTable function.
See Also
gpuDevice | gputimeit | tic | toc | gpuArray | arrayfun | pagefun | mexcuda