Tune Hyperparameters Using Reinforcement Learning Designer
This example shows how to tune agent hyperparameters using Reinforcement Learning Designer.
Introduction
The behavior of reinforcement learning algorithms depends on the set of hyperparameters you choose. The optimal set of hyperparameters varies depending on the application you use. The default set of hyperparameters often is not sufficient for the agent to learn the desired policy. When the default set of hyperparameters is not sufficient for training the agent, you can tune the hyperparameters. In this example, you tune the hyperparameters of a deep Q-network (DQN) agent for a discrete cart-pole environment using Reinforcement Learning Designer.
Open Reinforcement Learning Designer
Open the Reinforcement Learning Designer app.
You can open the app as follows:
From the MATLAB® Toolstrip — On the Apps tab, under Machine Learning and Deep Learning, click the Reinforcement Learning Designer icon.
At the MATLAB command prompt — Enter
reinforcementLearningDesigner.
For this example, use the MATLAB command prompt.
reinforcementLearningDesigner
Load Environment and Create Agent
To create a discrete action space cart-pole environment:
Navigate to the Reinforcement Learning tab and select New, in the Environment section.
Select Discrete Cart Pole from the list to create the environment in the app workspace.
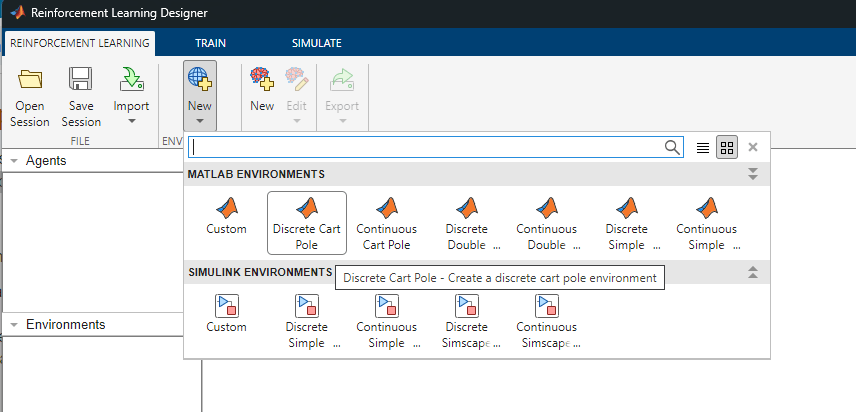
To create a DQN agent:
Select New, in the Agent section, to open the Create agent dialog box.
Select DQN as a compatible agent.
Press Ok to create the agent in the app workspace and to open the agent editor document.

Alternatively, select Import from the Reinforcement Learning tab to import your reinforcement learning environment and agent from the MATLAB workspace.
Tune Hyperparameters
You can tune the hyperparameters of your reinforcement learning agent with an exhaustive grid-based search approach or with a Bayesian optimization adaptive search approach. The Bayesian optimization approach requires the Statistics and Machine Learning Toolbox™. For detailed information about these approaches, see these examples:
The Reinforcement Learning Designer app automates several steps in these examples. You can tune hyperparameters with default settings or configure the settings before tuning.
In this section, you tune hyperparameters using default hyperparameter tuning settings. To configure hyperparameter tuning settings instead, see the Configure Tuning Options section.
To tune using default hyperparameter settings, follow these steps:
Navigate to the Train tab and specify the appropriate values for training options. For this example, only set Stopping Criteria to Average Reward.
Select Tune Hyperparameters to enable hyperparameter tuning.
If you have Parallel Computing Toolbox™ installed, select Use Parallel to speed up the tuning process using parallel workers. This step is optional.
Click Train to start tuning.

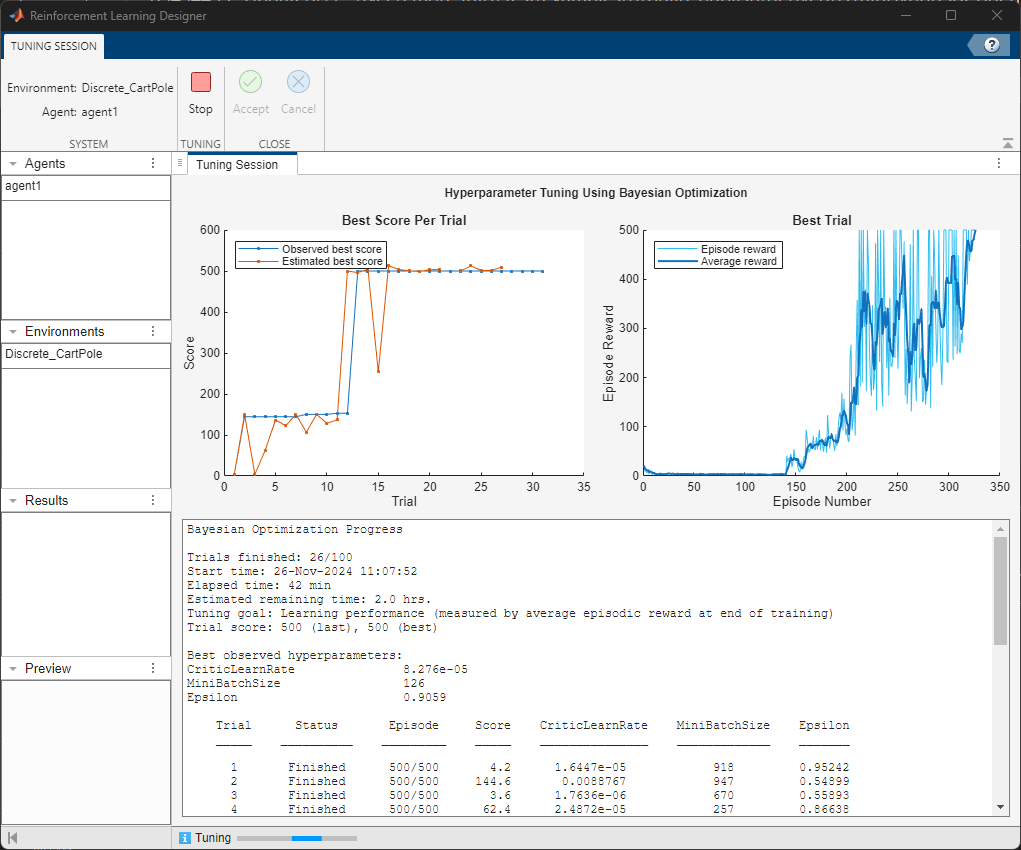
View the progress in the Tuning Session progress window:
The Best Score Per Trial plot shows the best observed scores (for this example, the average episodic reward) at the end of each trial. A trial is a training experiment for a particular combination of hyperparameters. Bayesian optimization uses a Gaussian process model to estimate the trial scores. This plot also shows the scores estimated by the model.
The Best Trial plot displays the episodic rewards from the best performing trial.
The verbose output panel displays the detailed tuning progress.
The trained agent and training result from each trial is saved in the Trials folder in the current directory.
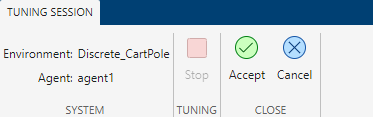
The tuning stops after the software runs the maximum number of trials. To manually stop the tuning at any time, select Stop from the Tuning Session tab. The software saves the best performing agent and tuning result in the app workspace.
The figure shows a snapshot of tuning progress using Bayesian optimization.
To validate the performance of the agent, follow these steps after the software finishes the tuning process:
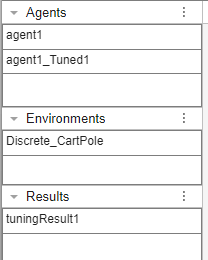
Select Accept to store the optimized agent and tuning results in the app workspace.
Open the agent Agent1_Tuned1 from the Agents panel and view the optimized hyperparameters.
Open tuningResult1 from the Results panel to view details of the tuning experiment.
Validate the performance of the agent from the Simulate tab. For more information, see Simulate Agent and Inspect Simulation Results.
Note:
The tuning process is computationally expensive and typically takes many hours to complete.
Due to randomness in the training process, your results might vary from the results shown in this example.
The algorithm automatically selects hyperparameters to tune and configures the search space appropriately.
By default, the software uses the Bayesian Optimization Algorithm (Statistics and Machine Learning Toolbox) to search for the optimal hyperparameter set with the maximum average episodic reward at the end of training. Using this algorithm requires the Statistics and Machine Learning Toolbox. If you do not have the toolbox, the algorithm uses an exhaustive grid-based search approach for optimizing the hyperparameters.
Configure Tuning Options
The default tuning settings might be sufficient for optimizing hyperparameters. However, you can configure the tuning settings to have more control over the tuning process. Follow these steps to configure the tuning settings:
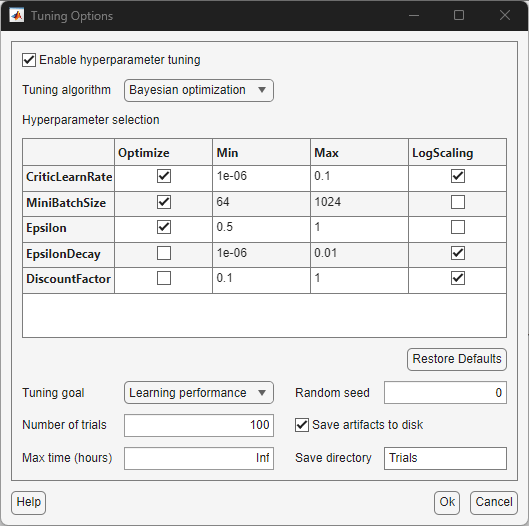
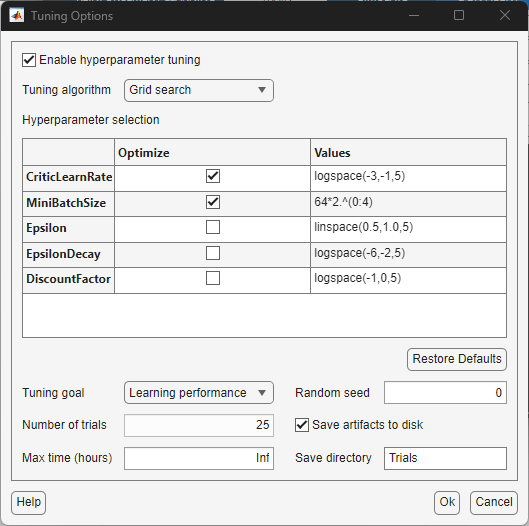
From the Train tab, in the Tune Hyperparameters list, select Hyperparameter tuning options to display the Tuning Options dialog box.

In the dialog box, under Tuning algorithm, select either Bayesian optimization or Grid search. Bayesian optimization performs an adaptive search on the hyperparameters space by updating a Gaussian process model. Grid search performs an exhaustive sweep over the hyperparameter space.
Under Hyperparameter selection, select or clear the check boxes in the Optimize column to configure which hyperparameters to optimize. For Bayesian optimization, configure the Min and Max values of the search space and enable or disable log scaling. For grid search, specify an expression for the hyperparameter search space. For example, to discretize the search space of the critic learning rate from
1e-3to1e-1with5points and log space scaling, specifylogspace(-3,-1,5)in the Values column. The expression must evaluate to a numeric array.Under Tuning goal, select Learning performance or Policy performance. If you select Learning performance, the score of the trial is the average episodic reward from the final episode of the training. If you select Policy performance, the score of the trial is the maximum agent evaluation statistic value over all training episodes. The evaluation statistic is the mean episodic reward from
5simulations periodically computed by an agent evaluator during the training.Under Number of trials, specify the maximum number of trials to perform.
Under Max time, specify the maximum number of hours for the tuning experiment.
Under Random seed, specify a positive integer to control the random seed at the beginning of each trial.
To save tuning artifacts (that is, the trained agent and training result from each trial), select Save artifacts to disk. Specify the folder name under Save directory.
Select Ok to confirm your choices or Cancel to discard your changes.
These figures show the default settings for Bayesian optimization and grid search configurations.
For more information about hyperparameter tuning options, see Specify Hyperparameter Tuning Options.
Generate Code
You can generate MATLAB code for the hyperparameter tuning process. The generated code can serve as a starting point to further customize the hyperparameter tuning process.
To generate code:
Optionally configure the hyperparameter tuning options using the instructions from the section above.
From the Train tab, select the environment and agent.
Select Tune Hyperparameters to enable tuning.
From the Train dropdown button list select Generate MATLAB function for hyperparameter tuning.

Here is a sample of the generated code.
function optimResults = runBayesoptTuningExperiment(agent,env) % Run a Bayesian hyperparameter tuning experiment. % Reinforcement Learning Toolbox % Generated on: 26-Nov-2024 13:18:47 arguments agent rl.agent.rlDQNAgent env rl.env.CartPoleDiscreteAction end % Define training options. % Here you can specify the options to train % your reinforcement learning agent. topts = rlTrainingOptions( ... MaxEpisodes=500, ... MaxStepsPerEpisode=500, ... Verbose=false, ... Plots="none", ... SimulationStorageType="none", ... StopTrainingCriteria="AverageReward", ... StopTrainingValue=500, ... StopOnError="on"); % Specify the hyperparameters to tune here. % For each hyperparameter, create an optimizableVariable object % with the appropriate range, transform and type, % and store it in the optimvars variable. % Then, in the objectiveFunction function at the end of this script, % configure the agent with the new hyperparameters. % A few hyperparameters are already configured for reference. optimvars(1) = optimizableVariable('CriticLearnRate',[1e-06 0.1], ... Transform='log',Type='real'); optimvars(2) = optimizableVariable('MiniBatchSize',[64 1024], ... Transform='none',Type='integer'); optimvars(3) = optimizableVariable('Epsilon',[0.5 1], ... Transform='none',Type='real'); % Run a Bayesian optimization experiment. objfun = @(params) objectiveFunction(params,agent,env,topts); optimResults = bayesopt(objfun,optimvars, ... MaxObjectiveEvaluations=100, ... MaxTime=Inf, ... Verbose=1, ... UseParallel=true); end %% Define local functions. function [objective,constraint,userData] = ... objectiveFunction(params,agent,env,topts) % Hyperparameter tuning objective function. % Fix random seed for reproducibility. rng(0,"twister"); % Copy the agent so that the trials start with the same learnables. ag = copy(agent); % Apply here the previously defined hyperparameters. % The params structure contains one combination of % the previously defined hyperparameters. for i = 1:numel(ag.AgentOptions.CriticOptimizerOptions) ag.AgentOptions.CriticOptimizerOptions(i).LearnRate = ... params.CriticLearnRate; end ag.AgentOptions.MiniBatchSize = params.MiniBatchSize; ag.AgentOptions.EpsilonGreedyExploration.Epsilon = params.Epsilon; % Run the training. result = train(ag,env,topts); % Compute the objective value. objective = -result.AverageReward(end); % Define constraint. constraint = []; % Store the trial result. userData.Agent = ag; userData.TrainingResult = result; end
Conclusion
The example demonstrates how you can tune agent hyperparameters using Reinforcement Learning Designer.
See Also
Apps
Functions
Objects
Topics
- Design and Train Agent Using Reinforcement Learning Designer
- Tune Hyperparameters Using Bayesian Optimization
- Train Agent or Tune Environment Parameters Using Parameter Sweeping
- Train Default DQN Agent to Balance Discrete Cart-Pole
- Load MATLAB Environments in Reinforcement Learning Designer
- Load Simulink Environments in Reinforcement Learning Designer
- Specify Training Options in Reinforcement Learning Designer
- Specify Simulation Options in Reinforcement Learning Designer
- Create Agents Using Reinforcement Learning Designer
- Train Reinforcement Learning Agents