plotconfusion
Plot classification confusion matrix
Syntax
Description
plotconfusion(
plots a confusion matrix for the true labels targets,outputs)targets and
predicted labels outputs. Specify the labels as categorical
vectors, or in one-of-N (one-hot) form.
Tip
plotconfusion is not recommended for categorical
labels. Use confusionchart instead.
On the confusion matrix plot, the rows correspond to the predicted class (Output Class) and the columns correspond to the true class (Target Class). The diagonal cells correspond to observations that are correctly classified. The off-diagonal cells correspond to incorrectly classified observations. Both the number of observations and the percentage of the total number of observations are shown in each cell.
The column on the far right of the plot shows the percentages of all the examples predicted to belong to each class that are correctly and incorrectly classified. These metrics are often called the precision (or positive predictive value) and false discovery rate, respectively. The row at the bottom of the plot shows the percentages of all the examples belonging to each class that are correctly and incorrectly classified. These metrics are often called the recall (or true positive rate) and false negative rate, respectively. The cell in the bottom right of the plot shows the overall accuracy.
plotconfusion(targets1,outputs1,name1,targets2,outputs2,name2,...,targetsn,outputsn,namen)
plots multiple confusion matrices in one figure and adds the
name arguments to the beginnings of the titles of the
corresponding plots.
Examples
Load the data consisting of synthetic images of handwritten digits. XTrain is a 28-by-28-by-1-by-5000 array of images and labelsTrain is a categorical vector containing the image labels.
load DigitsDataTrain
classNames = categories(labelsTrain);Define the architecture of a convolutional neural network.
layers = [
imageInputLayer([28 28 1])
convolution2dLayer(3,8,'Padding','same')
batchNormalizationLayer
reluLayer
convolution2dLayer(3,16,'Padding','same','Stride',2)
batchNormalizationLayer
reluLayer
convolution2dLayer(3,32,'Padding','same','Stride',2)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(10)
softmaxLayer];Specify training options and train the network.
options = trainingOptions('sgdm', ... 'MaxEpochs',5, ... 'Verbose',false, ... 'Plots','training-progress', ... 'Metrics','accuracy'); net = trainnet(XTrain,labelsTrain,layers,"crossentropy",options);
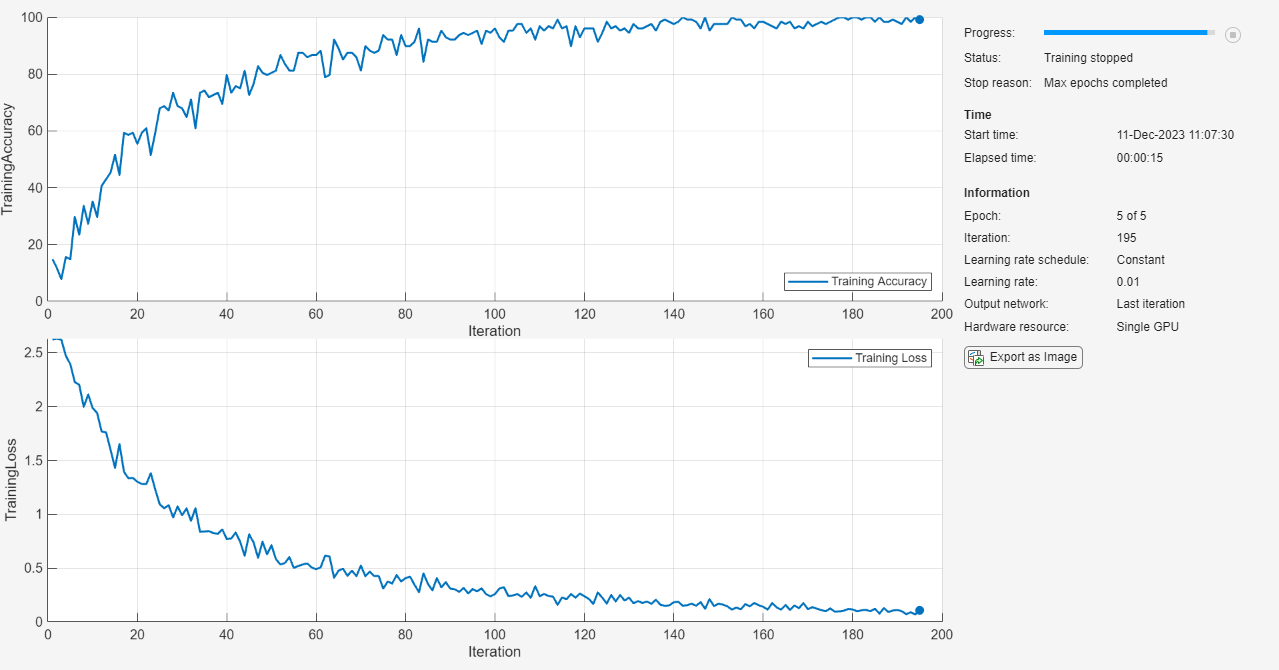
Load and classify test data using the trained network.
load DigitsDataTest
scores = minibatchpredict(net,XTest);
YTest = scores2label(scores,classNames);Plot the confusion matrix of the test labels and the predicted labels.
plotconfusion(labelsTest,YTest)

The rows correspond to the predicted class (Output Class) and the columns correspond to the true class (Target Class). The diagonal cells correspond to observations that are correctly classified. The off-diagonal cells correspond to incorrectly classified observations. Both the number of observations and the percentage of the total number of observations are shown in each cell.
The column on the far right of the plot shows the percentages of all the examples predicted to belong to each class that are correctly and incorrectly classified. These metrics are often called the precision (or positive predictive value) and false discovery rate, respectively. The row at the bottom of the plot shows the percentages of all the examples belonging to each class that are correctly and incorrectly classified. These metrics are often called the recall (or true positive rate) and false negative rate, respectively. The cell in the bottom right of the plot shows the overall accuracy.
Close all figures.
close(findall(groot,'Type','figure'))
Load sample data using the cancer_dataset function. XTrain is a 9-by-699 matrix defining nine attributes of 699 biopsies. YTrain is a 2-by-699 matrix where each column indicates the correct category of the corresponding observation. Each column of YTrain has one element that equals one in either the first or second row, corresponding to the cancer being benign or malignant, respectively. For more information on this dataset, type help cancer_dataset at the command line.
rng default
[XTrain,YTrain] = cancer_dataset;
YTrain(:,1:10)ans = 2×10
1 1 1 0 1 1 0 0 0 1
0 0 0 1 0 0 1 1 1 0
Create a pattern recognition network and train it using the sample data.
net = patternnet(10); net = train(net,XTrain,YTrain);
Estimate the cancer status using the trained network. Each column of the matrix YPredicted contains the predicted probabilities of each observation belonging to class 1 and class 2, respectively.
YPredicted = net(XTrain); YPredicted(:,1:10)
ans = 2×10
0.9980 0.9979 0.9894 0.0578 0.9614 0.9960 0.0026 0.0023 0.0084 0.9944
0.0020 0.0021 0.0106 0.9422 0.0386 0.0040 0.9974 0.9977 0.9916 0.0056
Plot the confusion matrix. To create the plot, plotconfusion labels each observation according to the highest class probability.
plotconfusion(YTrain,YPredicted)
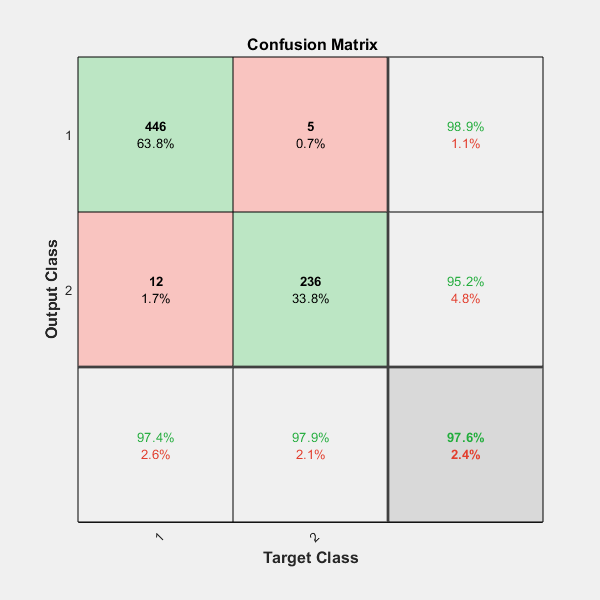
In this figure, the first two diagonal cells show the number and percentage of correct classifications by the trained network. For example, 446 biopsies are correctly classified as benign. This corresponds to 63.8% of all 699 biopsies. Similarly, 236 cases are correctly classified as malignant. This corresponds to 33.8% of all biopsies.
5 of the malignant biopsies are incorrectly classified as benign and this corresponds to 0.7% of all 699 biopsies in the data. Similarly, 12 of the benign biopsies are incorrectly classified as malignant and this corresponds to 1.7% of all data.
Out of 451 benign predictions, 98.9% are correct and 1.1% are wrong. Out of 248 malignant predictions, 95.2% are correct and 4.8% are wrong. Out of 458 benign cases, 97.4% are correctly predicted as benign and 2.6% are predicted as malignant. Out of 241 malignant cases, 97.9% are correctly classified as malignant and 2.1% are classified as benign.
Overall, 97.6% of the predictions are correct and 2.4% are wrong.
Input Arguments
Version History
Introduced in R2008a