addPix2PixHDLocalEnhancer
Add local enhancer network to pix2pixHD generator network
Syntax
Description
netWithEnhancer = addPix2PixHDLocalEnhancer(net)net.
For more information about the network architecture, see pix2pixHD Local Enhancer Network.
This function requires Deep Learning Toolbox™.
netWithEnhancer = addPix2PixHDLocalEnhancer(net,Name=Value)
Examples
Input Arguments
Name-Value Arguments
Output Arguments
More About
The addPix2PixHDLocalEnhancer function performs
these operations to add a local enhancer network to a pix2pixHD global generator network.
The default enhanced network follows the architecture proposed by Wang et. al. References.
The local enhancer network has an initial block of layers that accepts images of size [2*H 2*W C], where H is the height, W is the width, and C is the number of channels of the input to the global generator network,
net. Whennethas multiple image input layers, the input image size of the local enhancer network is twice the input size with the maximum resolution.After the initial block, the local enhancer network has a single downsampling block that downsamples the data by a factor of two. Therefore, the output after downsampling has size [H W 2*C].
The
addPix2PixHDLocalEnhancerfunction trims the final block from the global generator network. The function then adds the output of the last upsampling block in the global generator network to the output of the downsampled data from the enhancer network using anadditionLayer(Deep Learning Toolbox).The output of the addition then passes through
NumResidualBlocksresidual blocks from the local enhancer.The residual blocks are followed by a single upsampling block that upsamples data to size [2*H 2*W C].
The
addPix2PixHDLocalEnhancerfunction adds a final block to the enhanced network. The convolution layer has properties specified by the arguments ofaddPix2PixHDLocalEnhancer. If the global generator network has a final activation layer, then the function adds the same type of activation layer to the enhanced network.
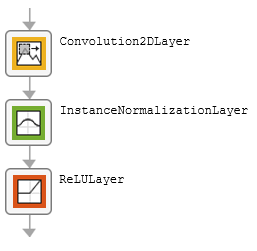
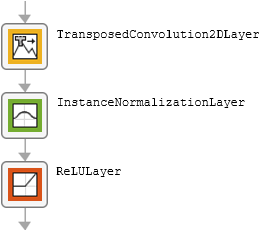
The table describes the blocks of layers that comprise the local enhancer network.
| Block Type | Layers | Diagram of Default Block |
|---|---|---|
| Initial block |
|
|
| Downsampling block |
|
|
| Residual block |
|
|
| Upsampling block |
|
|
| Final block |
|
|



References
[1]
Version History
Introduced in R2021a