trainnet
Syntax
Description
netTrained = trainnet(images,net,lossFcn,options)net for image tasks using the
images and targets specified by images and the training options
defined by options.
netTrained = trainnet(sequences,net,lossFcn,options)sequences.
netTrained = trainnet(features,net,lossFcn,options)features.
netTrained = trainnet(data,net,lossFcn,options)
[ also returns information on the training using any of
the previous syntaxes.netTrained,info]
= trainnet(___)
Examples
If you have a data set of images, then you can train a deep neural network using an image input layer.
Unzip the digit sample data and create an image datastore. The imageDatastore function automatically labels the images based on folder names.
unzip("DigitsData.zip") imds = imageDatastore("DigitsData", ... IncludeSubfolders=true, ... LabelSource="foldernames");
Divide the data into training and test data sets, so that each category in the training set contains 750 images, and the test set contains the remaining images from each label. splitEachLabel splits the image datastore into two new datastores for training and test.
numTrainFiles = 750;
[imdsTrain,imdsTest] = splitEachLabel(imds,numTrainFiles,"randomized");Define the convolutional neural network architecture. Specify the size of the images in the input layer of the network and the number of classes in the final fully connected layer. Each image is 28-by-28-by-1 pixels.
inputSize = [28 28 1];
classNames = categories(imds.Labels);
numClasses = numel(classNames);
layers = [
imageInputLayer(inputSize)
convolution2dLayer(5,20)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];Specify the training options.
Train using the SGDM solver.
Train for four epochs.
Monitor the training progress in a plot and monitor the accuracy metric.
Disable the verbose output.
options = trainingOptions("sgdm", ... MaxEpochs=4, ... Verbose=false, ... Plots="training-progress", ... Metrics="accuracy");
Train the neural network. For classification, use cross-entropy loss.
net = trainnet(imdsTrain,layers,"crossentropy",options);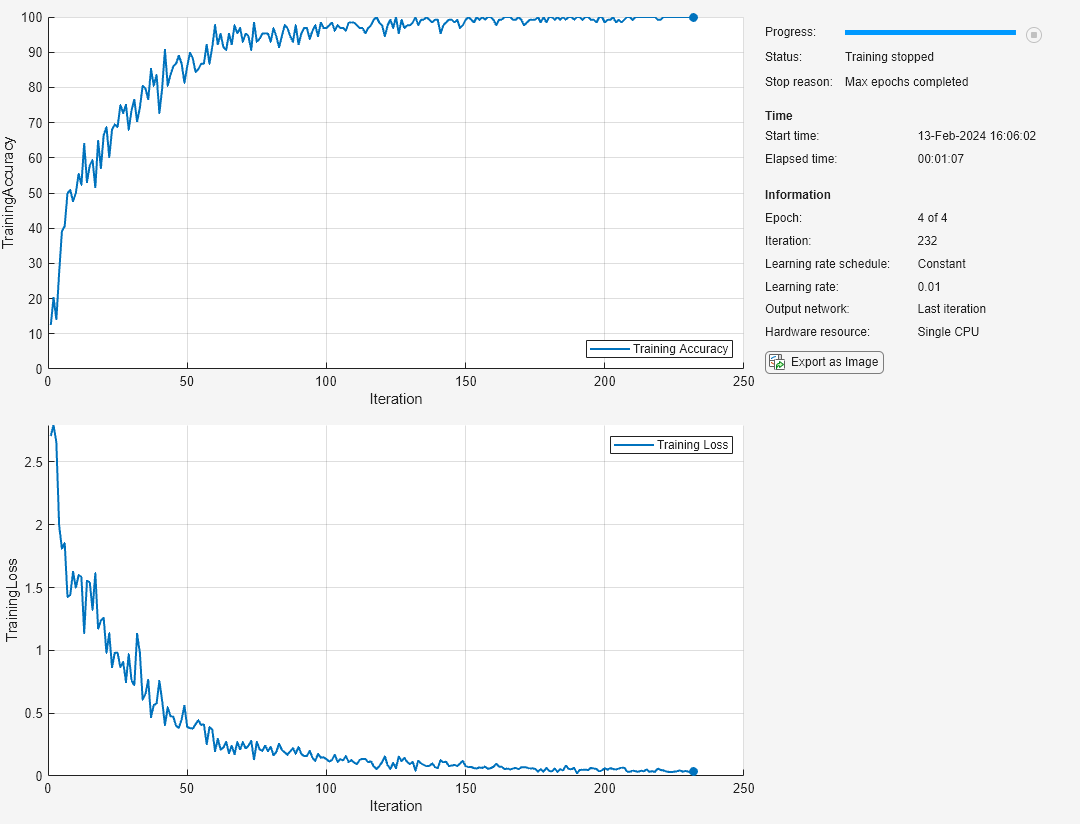
Test the network using the labeled test set. For single-label classification, evaluate the accuracy. The accuracy is the percentage of the labels that the network predicts correctly.
accuracy = testnet(net,imdsTest,"accuracy")accuracy = 98.2400
Predict the classification scores using the trained network, then convert the labels to predictions using the scores2label function.
scoresTest = minibatchpredict(net,imdsTest); YTest = scores2label(scoresTest,classNames);
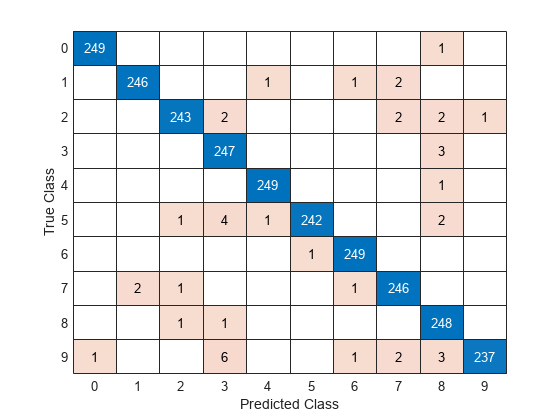
Visualize the predictions in a confusion chart.
confusionchart(imdsTest.Labels,YTest)
If you have a data set of numeric features (for example tabular data without spatial or time dimensions), then you can train a deep neural network using a feature input layer.
Read the transmission casing data from the CSV file "transmissionCasingData.csv".
filename = "transmissionCasingData.csv"; tbl = readtable(filename,TextType="String");
Convert the labels for prediction to categorical using the convertvars function.
labelName = "GearToothCondition"; tbl = convertvars(tbl,labelName,"categorical");
To train a network using categorical features, you must first convert the categorical features to numeric. First, convert the categorical predictors to categorical using the convertvars function by specifying a string array containing the names of all the categorical input variables. In this data set, there are two categorical features with names "SensorCondition" and "ShaftCondition".
categoricalPredictorNames = ["SensorCondition" "ShaftCondition"]; tbl = convertvars(tbl,categoricalPredictorNames,"categorical");
Loop over the categorical input variables. For each variable, convert the categorical values to one-hot encoded vectors using the onehotencode function.
for i = 1:numel(categoricalPredictorNames) name = categoricalPredictorNames(i); tbl.(name) = onehotencode(tbl.(name),2); end
View the first few rows of the table. Notice that the categorical predictors have been split into multiple columns.
head(tbl)
SigMean SigMedian SigRMS SigVar SigPeak SigPeak2Peak SigSkewness SigKurtosis SigCrestFactor SigMAD SigRangeCumSum SigCorrDimension SigApproxEntropy SigLyapExponent PeakFreq HighFreqPower EnvPower PeakSpecKurtosis SensorCondition ShaftCondition GearToothCondition
________ _________ ______ _______ _______ ____________ ___________ ___________ ______________ _______ ______________ ________________ ________________ _______________ ________ _____________ ________ ________________ _______________ ______________ __________________
-0.94876 -0.9722 1.3726 0.98387 0.81571 3.6314 -0.041525 2.2666 2.0514 0.8081 28562 1.1429 0.031581 79.931 0 6.75e-06 3.23e-07 162.13 0 1 1 0 No Tooth Fault
-0.97537 -0.98958 1.3937 0.99105 0.81571 3.6314 -0.023777 2.2598 2.0203 0.81017 29418 1.1362 0.037835 70.325 0 5.08e-08 9.16e-08 226.12 0 1 1 0 No Tooth Fault
1.0502 1.0267 1.4449 0.98491 2.8157 3.6314 -0.04162 2.2658 1.9487 0.80853 31710 1.1479 0.031565 125.19 0 6.74e-06 2.85e-07 162.13 0 1 0 1 No Tooth Fault
1.0227 1.0045 1.4288 0.99553 2.8157 3.6314 -0.016356 2.2483 1.9707 0.81324 30984 1.1472 0.032088 112.5 0 4.99e-06 2.4e-07 162.13 0 1 0 1 No Tooth Fault
1.0123 1.0024 1.4202 0.99233 2.8157 3.6314 -0.014701 2.2542 1.9826 0.81156 30661 1.1469 0.03287 108.86 0 3.62e-06 2.28e-07 230.39 0 1 0 1 No Tooth Fault
1.0275 1.0102 1.4338 1.0001 2.8157 3.6314 -0.02659 2.2439 1.9638 0.81589 31102 1.0985 0.033427 64.576 0 2.55e-06 1.65e-07 230.39 0 1 0 1 No Tooth Fault
1.0464 1.0275 1.4477 1.0011 2.8157 3.6314 -0.042849 2.2455 1.9449 0.81595 31665 1.1417 0.034159 98.838 0 1.73e-06 1.55e-07 230.39 0 1 0 1 No Tooth Fault
1.0459 1.0257 1.4402 0.98047 2.8157 3.6314 -0.035405 2.2757 1.955 0.80583 31554 1.1345 0.0353 44.223 0 1.11e-06 1.39e-07 230.39 0 1 0 1 No Tooth Fault
View the class names of the data set.
classNames = categories(tbl{:,labelName})classNames = 2×1 cell
{'No Tooth Fault'}
{'Tooth Fault' }
Set aside data for testing. Partition the data into a training set containing 85% of the data and a test set containing the remaining 15% of the data. To partition the data, use the trainingPartitions function, attached to this example as a supporting file. To access this file, open the example as a live script.
numObservations = size(tbl,1); [idxTrain,idxTest] = trainingPartitions(numObservations,[0.85 0.15]); tblTrain = tbl(idxTrain,:); tblTest = tbl(idxTest,:);
Convert the data to a format that the trainnet function supports. Convert the predictors and targets to numeric and categorical arrays, respectively. For feature input, the network expects data with rows that correspond to observations and columns that correspond to the features. If your data has a different layout, then you can preprocess your data to have this layout or you can provide layout information using data formats. For more information, see Deep Learning Data Formats.
predictorNames = ["SigMean" "SigMedian" "SigRMS" "SigVar" "SigPeak" "SigPeak2Peak" ... "SigSkewness" "SigKurtosis" "SigCrestFactor" "SigMAD" "SigRangeCumSum" ... "SigCorrDimension" "SigApproxEntropy" "SigLyapExponent" "PeakFreq" ... "HighFreqPower" "EnvPower" "PeakSpecKurtosis" "SensorCondition" "ShaftCondition"]; XTrain = table2array(tblTrain(:,predictorNames)); TTrain = tblTrain.(labelName); XTest = table2array(tblTest(:,predictorNames)); TTest = tblTest.(labelName);
Define a network with a feature input layer and specify the number of features. Also, configure the input layer to normalize the data using Z-score normalization.
numFeatures = size(XTrain,2);
numClasses = numel(classNames);
layers = [
featureInputLayer(numFeatures,Normalization="zscore")
fullyConnectedLayer(16)
layerNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];Specify the training options:
Train using the L-BFGS solver. This solver suits tasks with small networks and when the data fits in memory.
Train using the CPU. Because the network and data is small, the CPU is better suited.
Display the training progress in a plot.
Suppress the verbose output.
options = trainingOptions("lbfgs", ... ExecutionEnvironment="cpu", ... Plots="training-progress", ... Verbose=false);
Train the network using the trainnet function. For classification, use cross-entropy loss.
net = trainnet(XTrain,TTrain,layers,"crossentropy",options);
Test the network using the labeled test set. For single-label classification, evaluate the accuracy. The accuracy is the percentage of the labels that the network predicts correctly.
accuracy = testnet(net,XTest,TTest,"accuracy")accuracy = 100
Predict the labels of the test data using the trained network. Predict the classification scores using the trained network then convert the predictions to labels using the scores2label function.
scoresTest = minibatchpredict(net,XTest); YTest = scores2label(scoresTest,classNames);
Visualize the predictions in a confusion chart.
confusionchart(TTest,YTest)

Input Arguments
Output Arguments
More About
Tips
For regression tasks, normalizing the targets using the
NormalizeTargetsargument of thetrainingOptionsfunction often helps to stabilize and speed up training. For more information, see Train Convolutional Neural Network for Regression.In most cases, if the predictor or targets contain
NaNvalues, then they are propagated through the network and the training fails to converge.To convert a numeric array to a datastore, use an
ArrayDatastoreobject.When you combine layers in a neural network with mixed types of data, you may need to reformat the data before passing it to a combination layer (such as a concatenation or an addition layer). To reformat the data, you can use a flatten layer to flatten the spatial dimensions into the channel dimension, or create a
FunctionLayerobject or custom layer that reformats and reshapes the data.