Transfer Learning with Pretrained Audio Networks
This example shows how to use transfer learning to retrain YAMNet, a pretrained convolutional neural network, to classify a new set of audio signals. To get started with audio deep learning from scratch, see Classify Sound Using Deep Learning.
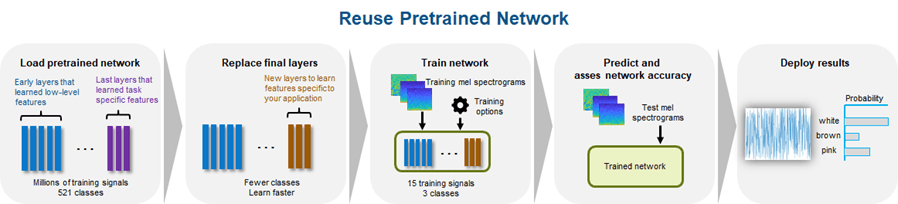
Transfer learning is commonly used in deep learning applications. You can take a pretrained network and use it as a starting point to learn a new task. Fine-tuning a network with transfer learning is usually much faster and easier than training a network with randomly initialized weights from scratch. You can quickly transfer learned features to a new task using a smaller number of training signals.
Audio Toolbox™ additionally provides the classifySound function, which implements necessary preprocessing for YAMNet and convenient postprocessing to interpret the results. Audio Toolbox also provides the pretrained VGGish network (vggish) as well as the vggishEmbeddings function, which implements preprocessing and postprocessing for the VGGish network.
Create Data
Generate 100 white noise signals, 100 brown noise signals, and 100 pink noise signals. Each signal represents a duration of 0.98 seconds assuming a 16 kHz sample rate.
fs = 16e3; duration = 0.98; N = duration*fs; numSignals = 100; wNoise = 2*rand([N,numSignals]) - 1; wLabels = repelem(categorical("white"),numSignals,1); bNoise = filter(1,[1,-0.999],wNoise); bNoise = bNoise./max(abs(bNoise),[],"all"); bLabels = repelem(categorical("brown"),numSignals,1); pNoise = pinknoise([N,numSignals]); pLabels = repelem(categorical("pink"),numSignals,1);
Split the data into training and test sets. Normally, the training set consists of most of the data. However, to illustrate the power of transfer learning, you will use only a few samples for training and the majority for validation.
K =5; trainAudio = [wNoise(:,1:K),bNoise(:,1:K),pNoise(:,1:K)]; trainLabels = [wLabels(1:K);bLabels(1:K);pLabels(1:K)]; validationAudio = [wNoise(:,K+1:end),bNoise(:,K+1:end),pNoise(:,K+1:end)]; validationLabels = [wLabels(K+1:end);bLabels(K+1:end);pLabels(K+1:end)]; fprintf("Number of samples per noise color in train set = %d\n" + ... "Number of samples per noise color in validation set = %d\n",K,numSignals-K);
Number of samples per noise color in train set = 5 Number of samples per noise color in validation set = 95
Extract Features
Use yamnetPreprocess to extract log-mel spectrograms from both the training set and the validation set using the same parameters as the YAMNet model was trained on.
trainFeatures = yamnetPreprocess(trainAudio,fs); validationFeatures = yamnetPreprocess(validationAudio,fs);
Transfer Learning
To load the pretrained network, call yamnet. If the Audio Toolbox model for YAMNet is not installed, then the function provides a link to the location of the network weights. To download the model, click the link. Unzip the file to a location on the MATLAB path. The YAMNet model can classify audio into one of 521 sound categories, including white noise and pink noise (but not brown noise).
net = yamnet; net.Layers(end).Classes
ans = 521×1 categorical array
"Speech"
"Child speech, kid speaking"
"Conversation"
"Narration, monologue"
"Babbling"
"Speech synthesizer"
"Shout"
"Bellow"
"Whoop"
"Yell"
⋮
Prepare the model for transfer learning by first converting the network to a layerGraph (Deep Learning Toolbox). Use replaceLayer (Deep Learning Toolbox) to replace the fully-connected layer with an untrained fully-connected layer. Replace the classification layer with a classification layer that classifies the input as "white", "pink", or "brown". See List of Deep Learning Layers (Deep Learning Toolbox) for deep learning layers supported in MATLAB®.
uniqueLabels = unique(trainLabels); numLabels = numel(uniqueLabels); lgraph = layerGraph(net.Layers); lgraph = replaceLayer(lgraph,"dense",fullyConnectedLayer(numLabels,Name="dense")); lgraph = replaceLayer(lgraph,"Sound",classificationLayer(Name="Sounds",Classes=uniqueLabels));
To define training options, use trainingOptions (Deep Learning Toolbox).
options = trainingOptions("adam",ValidationData={single(validationFeatures),validationLabels});To train the network, use trainNetwork (Deep Learning Toolbox). The network achieves a validation accuracy of 100% using only 5 signals per noise type.
trainNetwork(single(trainFeatures),trainLabels,lgraph,options);
Training on single CPU. |======================================================================================================================| | Epoch | Iteration | Time Elapsed | Mini-batch | Validation | Mini-batch | Validation | Base Learning | | | | (hh:mm:ss) | Accuracy | Accuracy | Loss | Loss | Rate | |======================================================================================================================| | 1 | 1 | 00:00:01 | 20.00% | 88.42% | 1.1922 | 0.6651 | 0.0010 | | 30 | 30 | 00:00:14 | 100.00% | 100.00% | 5.0068e-06 | 0.0003 | 0.0010 | |======================================================================================================================| Training finished: Max epochs completed.