Measuring Speech Intelligibility and Perceived Audio Quality with STOI and ViSQOL
Evaluating speech and audio quality is fundamental to the development of communication and speech enhancement systems. In speech communication systems, it is necessary to evaluate signal integrity, speech intelligibility, and perceived audio quality. The goal of a speech communication system is to provide to the end-user the perception of a high-quality representation that meets their expectations of the original signal input. Subjective listening tests are the ground truth for evaluating speech and audio quality, but are time consuming and expensive. Objective measures of speech and audio quality have been an active research area for decades and continue to evolve with the technology of communication, recording, and speech enhancement.
Speech and audio quality measures can be classified as intrusive and non-intrusive. Intrusive measurements have access to both the reference audio and the audio output from a processing system. Intrusive measurements give a score based on the perceptually-motivated differences between the two. Non-intrusive measurements evaluate the audio output from a processing system without access to the reference audio. Non-intrusive measurements generally require knowledge of the speech or sound production mechanisms to evaluate the goodness of the output. Both metrics presented in this example are intrusive.
The short-time objective intelligibility (STOI) metric was introduced in 2010 [1] for the evaluation of noisy speech and time-frequency weighted (enhanced) noisy speech. It was subsequently expanded on and extended in [2] and [3]. The STOI algorithm was shown to be strongly correlated with speech intelligibility in subjective listening tests. Speech intelligibility is measured by the ratio of words correctly understood under different listening conditions. Listening conditions used in the development of STOI include time-frequency masks applied to speech signals to mimic speech enhancement, and the simulation of additive noise conditions such as cafeteria, factor, car, and speech-shaped noise.
The virtual speech quality objective listener metric (ViSQOL) was introduced in 2012 [4] based on prior work on the Neurogram Similarity Index Measure (NSIM) [5,6]. This metric was designed for the evaluation of speech quality in processed speech signals, and it was extended for general audio [7]. This metric objectively measures the perceived quality of speech and/or audio, taking into account various aspects of human auditory perception. The algorithm also compensates for temporal differences introduced by jitter, drift, or packet loss. Similar to STOI, ViSQOL offers a valuable alternative to time-consuming and expensive subjective listening tests by simulating the human auditory system. Its ability to capture the nuances of human perception makes it a valuable addition to the arsenal of tools for assessing speech and audio quality.
This example creates test data and uses both STOI and ViSQOL to evaluate a speech processing system. The last section in this example, Evaluate Speech Enhancement System, requires Deep Learning Toolbox™.
Create Test Data
Use the getTestSignals supporting function to create a reference and degraded signal pair. The getTestSignals supporting function uses the specified signal and noise files and creates a reference signal and corresponding degraded signal at the requested SNR and duration.
fs = 16e3; signal ="Rainbow-16-8-mono-114secs.wav"; noise =
"MainStreetOne-16-16-mono-12secs.wav"; [ref,deg10] = getTestSignals(SampleRate=fs,SNR=10,Duration=10,Noise=noise,Reference=signal);
Visualize and listen to the reference signal.
t = (1/fs)*(0:numel(ref) - 1); plot(t,ref) title("Reference Signal") xlabel("Time (s)")

sound(ref,fs)
Visualize and listen to the degraded signal.
plot(t,deg10) title("Degraded Signal") xlabel("Time (s)")
sound(deg10,fs)
Short-Time Objective Intelligibility (STOI)
The STOI algorithm assumes a speech signal is present. The algorithm first discards regions of silence, and then compares the energy of perceptually-spaced frequency bands of the original and target signals. The intermediate analysis time scale is relatively small, approximately 386 ms. The final objective intelligibility is the mean of the intermediate measures.
The authors of STOI designed the algorithm to optimize speed and simplicity. These attributes have made STOI a popular tool to evaluate speech degradation and speech enhancement systems. The simplicity and speed have also enabled STOI to be used as a loss function when training deep learning models.
The algorithm implemented by Audio Toolbox has made some modifications such as an improved resampling and an improvement to the re-composition issues introduced by the VAD in the original implementation. Additionally, the algorithm has been reformulated for increased parallelization. These changes do result in slightly different numerics when compared to the original implementation.
Call stoi with the degraded signal, reference signal, and the common sample rate. While the stoi function accepts arbitrary sample rates, signals are resampled internally to 10 kHz.
metric = stoi(deg10,ref,fs)
metric = 0.8465
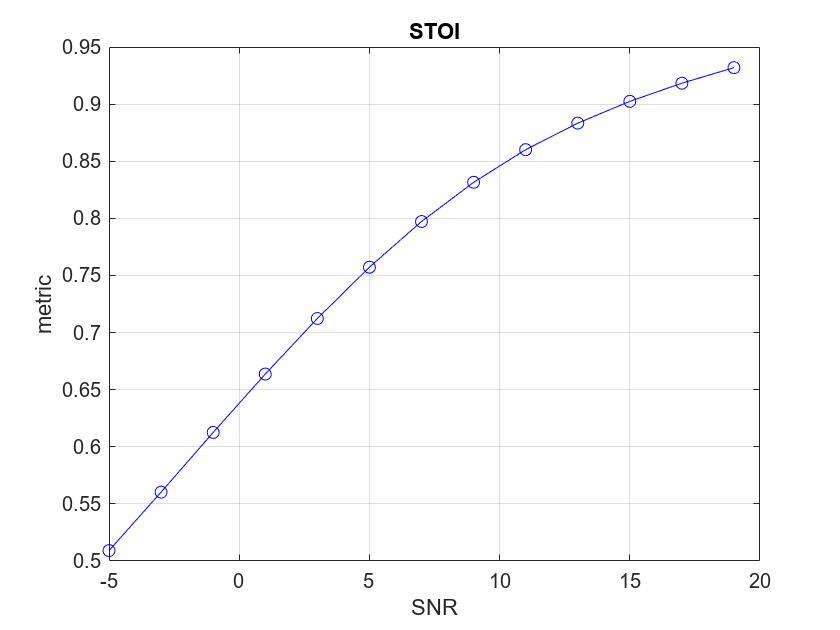
You can explore how the STOI algorithm behaves under different signal, noise, and mixture conditions by modifying the test parameters below. While the theoretical range returned from STOI is [-1,1], the practical range is closer to [0.4,1]. When the STOI metric approaches 0.4 the speech approaches unintelligibility.
fs =16e3; snrSweep =
-5:2:
20; duration =
10; signal =
"Rainbow-16-8-mono-114secs.wav"; noise =
"MainStreetOne-16-16-mono-12secs.wav"; deg = zeros(size(deg10,1),numel(snrSweep)); for ii = 1:numel(snrSweep) [~,deg(:,ii)] = getTestSignals(SNR=snrSweep(ii),SampleRate=fs,Duration=duration,Noise=noise,Reference=signal); end
Calculate the STOI metric for each degraded signal.
stoi_d = zeros(size(snrSweep)); for ii = 1:numel(snrSweep) stoi_d(ii) = stoi(deg(:,ii),ref,fs); end
Plot the STOI metric against the SNR sweep for the signals under test.
plot(snrSweep,stoi_d,"bo", ... snrSweep,stoi_d,"b-") xlabel("SNR") ylabel("metric") title("STOI") grid on
Virtual Speech Quality Objective Listener (ViSQOL)
The ViSQOL algorithm includes a time-matching algorithm to align the input and degraded signals automatically. Not only is there a global alignment that applies to the whole processed signal, there is also a granular matching of so-called "patches", corresponding to short periods of time. This allows the alignment to work with signals that may drift or suffer from lost samples.
ViSQOL has both a speech mode and an audio mode. In speech mode, a voice activity detector (VAD) algorithm removes irrelevant portions of the signal.
Once the signals are aligned, ViSQOL computes the Neurogram Similarity Index Measure (NSIM) in the time-frequency domain (based on a spectrogram).
ViSQOL can provide an overall NSIM score, a Mean Opinion Score (MOS), and specific information about each time patch and frequency bin.
Call visqol with the degraded signal, reference signal, and the common sample rate. Use a sample rate of 16 kHz for speech, or 48 kHz for audio, and set Mode correspondingly. The alignment procedure can be the most time consuming, so the SearchWindowSize option can be set to zero in cases the degraded signal is known to have constant latency (ex: no dropped samples or drift). The OutputMetric and ScaleMOS options determine which metric is returned (ex: NSIM and/or MOS).
Calculate the ViSQOL metrics for each degraded signal.
visqol_d = zeros(numel(snrSweep),2); for ii = 1:numel(snrSweep) visqol_d(ii,:) = visqol(deg(:,ii),ref,fs,Mode="speech",OutputMetric="MOS and NSIM"); end
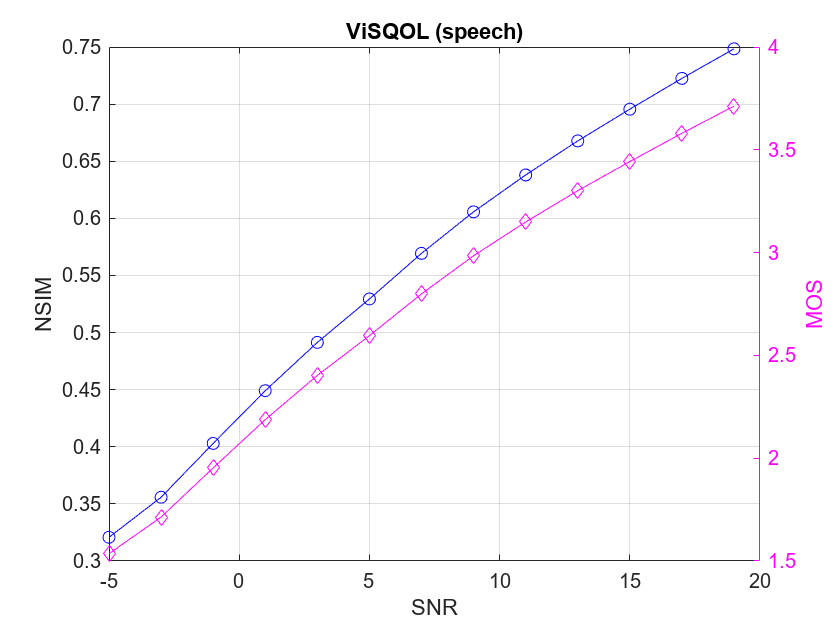
Plot the ViSQOL MOS and NSIM metrics against the SNR sweep for the signals under test. The NSIM metric is a normalized value between -1 and 1 (but generally positive), while the MOS metric is in the 1 to 5 range as seen in traditional listening tests.
figure plot(snrSweep,visqol_d(:,2),"bo", ... snrSweep,visqol_d(:,2),"b-") xlabel("SNR") ylabel("NSIM") title("ViSQOL (speech)") hold on yyaxis right plot(snrSweep,visqol_d(:,1),"md", ... snrSweep,visqol_d(:,1),"m-") set(gca,YColor="m"); ylabel("MOS") grid on hold off
The signals are not just composed of clean speech, so compute the ViSQOL metric in audio mode to see how the results change.
deg48 = audioresample(deg,InputRate=fs,OutputRate=48e3); ref48 = audioresample(ref,InputRate=fs,OutputRate=48e3); visqol_d = zeros(numel(snrSweep),2); for ii = 1:numel(snrSweep) visqol_d(ii,:) = visqol(deg48(:,ii),ref48,fs,Mode="audio",OutputMetric="MOS and NSIM"); end figure plot(snrSweep,visqol_d(:,2),"bo", ... snrSweep,visqol_d(:,2),"b-") xlabel("SNR") ylabel("NSIM") title("ViSQOL (audio)") hold on yyaxis right plot(snrSweep,visqol_d(:,1),"md", ... snrSweep,visqol_d(:,1),"m-") set(gca,YColor="m"); ylabel("MOS") grid on hold off

Evaluate Speech Enhancement System
Both STOI and ViSQOL are used for the evaluation of speech enhancement systems.
To perform speech enhancement, use enhanceSpeech. This functionality requires Deep Learning Toolbox™.
Enhance the sweep of degraded speech developed previously.
enh = zeros(size(deg)); for ii = 1:numel(snrSweep) enh(:,ii) = enhanceSpeech(deg(:,ii),fs); end
Calculate the STOI and ViSQOL NSIM metrics for each of the degraded speech signals.
stoi_e = zeros(size(snrSweep)); nsim_e = zeros(size(snrSweep)); for ii = 1:numel(snrSweep) stoi_e(ii) = stoi(enh(:,ii),ref,fs); nsim_e(ii) = visqol(enh(:,ii),ref,fs,Mode="speech",OutputMetric="NSIM"); end
Plot the STOI metric against the SNR sweep for both the degraded and enhanced speech signals. The speech enhancement model appears to perform best around 0 dB SNR, and actually decreases the STOI metric above 15 dB SNR. When the noise level is very low, the artifacts introduced by the speech enhancement system become more pronounced. When the noise level is very high, the speech enhancement system has difficulty isolating the speech for enhancement, and sometimes instead makes noise signals louder.
figure plot(snrSweep,stoi_d,"b-", ... snrSweep,stoi_e,"r-", ... snrSweep,stoi_d,"bo", ... snrSweep,stoi_e,"ro") xlabel("SNR") ylabel("STOI") title("Speech Enhancement Performance Evaluation") legend("Degraded","Enhanced",Location="best") grid on

Plot the ViSQOL metric against the SNR sweep for both the degraded and enhanced speech signals.
figure plot(snrSweep,visqol_d(:,2),"b-", ... snrSweep,nsim_e,"r-", ... snrSweep,visqol_d(:,2),"bo", ... snrSweep,nsim_e,"ro") xlabel("SNR") ylabel("NSIM") title("ViSQOL") legend("Degraded","Enhanced",Location="best") grid on

Supporting Functions
Mix SNR
function [noisySignal,requestedNoise] = mixSNR(signal,noise,ratio) % [noisySignal,requestedNoise] = mixSNR(signal,noise,ratio) returns a noisy % version of the signal, noisySignal. The noisy signal has been mixed with % noise at the specified ratio in dB. signalNorm = norm(signal); noiseNorm = norm(noise); goalNoiseNorm = signalNorm/(10^(ratio/20)); factor = goalNoiseNorm/noiseNorm; requestedNoise = noise.*factor; noisySignal = signal + requestedNoise; noisySignal = noisySignal./max(abs(noisySignal)); end
Get Test Signals
function [ref,deg] = getTestSignals(options) arguments options.SNR options.SampleRate options.Duration options.Reference options.Noise end [ref,xfs] = audioread(options.Reference); [n,nfs] = audioread(options.Noise); ref = audioresample(ref,InputRate=xfs,OutputRate=options.SampleRate); n = audioresample(n,InputRate=nfs,OutputRate=options.SampleRate); ref = mean(ref,2); n = mean(n,2); numsamples = round(options.SampleRate*options.Duration); ref = resize(ref,numsamples,Pattern="circular"); n = resize(n,numsamples,Patter="circular"); deg = mixSNR(ref,n,options.SNR); ref = ref./max(abs(ref)); end
References
[1] C.H.Taal, R.C.Hendriks, R.Heusdens, J.Jensen, "A Short-Time Objective Intelligibility Measure for Time-Frequency Weighted Noisy Speech," ICASSP 2010, Dallas, Texas, US.
[2] C.H.Taal, R.C.Hendriks, R.Heusdens, J.Jensen, "An Algorithm for Intelligibility Prediction of Time-Frequency Weighted Noisy Speech," IEEE Transactions on Audio, Speech, and Language Processing, 2011.
[3] Jesper Jensen and Cees H. Taal, "An Algorithm for Predicting the Intelligibility of Speech Masked by Modulated Noise Maskers," IEEE Transactions on Audio, Speech and Language Processing, 2016.
[4] A. Hines, J. Skoglund, A. Kokaram, N. Harte, "ViSQOL: The Virtual Speech Quality Objective Listener," International Workshop on Acoustic Signal Enhancement 2012, 4-6 September 2012, Aachen, DE.
[5] A. Hines and N. Harte, “Speech Intelligibility Prediction using a Neurogram Similarity Index Measure,” Speech Communication, vol. 54, no. 2, pp.306-320, 2012.
[6] A. Hines, "Predicting Speech Intelligibility", Doctoral Thesis, Trinity College Dublin, 2012.
[7] A. Hines, E. Gillen, D. Kelly, J. Skoglund, A. Kokaram, N. Harte, "ViSQOLAudio: An objective audio quality metric for low bitrate codecs," Journal of the Acoustical Society of America, vol. 137, no. 6, 2015.
See Also
stoi | visqol | enhanceSpeech