voiceActivityDetector
Detect presence of speech in audio signal
Description
The voiceActivityDetector
System object™ detects the presence of speech in an audio segment. You can also use the
voiceActivityDetector
System object to output an estimate of the noise variance per frequency bin.

To detect the presence of speech:
Create the
voiceActivityDetectorobject and set its properties.Call the object with arguments, as if it were a function.
To learn more about how System objects work, see What Are System Objects?
Creation
Description
VAD = voiceActivityDetector creates a System object, VAD, that detects the presence of speech independently
across each input channel.
VAD = voiceActivityDetector( sets
each property Name,Value)Name to the specified Value.
Unspecified properties have default values.
Example: VAD = voiceActivityDetector('InputDomain','Frequency')
creates a System object, VAD, that accepts frequency-domain input.
Properties
Usage
Description
[
applies a voice activity detector on the input, probability,noiseEstimate]
= VAD(audioIn)audioIn, and returns
the probability that speech is present. It also returns the estimated noise variance per
frequency bin.
Input Arguments
Output Arguments
Object Functions
To use an object function, specify the
System object as the first input argument. For
example, to release system resources of a System object named obj, use
this syntax:
release(obj)
Examples
Use the default voiceActivityDetector System object™ to detect the presence of speech in a streaming audio signal.
Create an audio file reader to stream an audio file for processing. Define parameters to chunk the audio signal into 10 ms non-overlapping frames.
fileReader = dsp.AudioFileReader('Counting-16-44p1-mono-15secs.wav');
fs = fileReader.SampleRate;
fileReader.SamplesPerFrame = ceil(10e-3*fs);
Create a default voiceActivityDetector System object to detect the presence of speech in the audio file.
VAD = voiceActivityDetector;
Create a scope to plot the audio signal and corresponding probability of speech presence as detected by the voice activity detector. Create an audio device writer to play the audio through your sound card.
scope = timescope( ... 'NumInputPorts',2, ... 'SampleRate',fs, ... 'TimeSpanSource','Property','TimeSpan',3, ... 'BufferLength',3*fs, ... 'YLimits',[-1.5 1.5], ... 'TimeSpanOverrunAction','Scroll', ... 'ShowLegend',true, ... 'ChannelNames',{'Audio','Probability of speech presence'}); deviceWriter = audioDeviceWriter('SampleRate',fs);
In an audio stream loop:
Read from the audio file.
Calculate the probability of speech presence.
Visualize the audio signal and speech presence probability.
Play the audio signal through your sound card.
while ~isDone(fileReader) audioIn = fileReader(); probability = VAD(audioIn); scope(audioIn,probability*ones(fileReader.SamplesPerFrame,1)) deviceWriter(audioIn); end

Use a voice activity detector to detect the presence of speech in an audio signal. Plot the probability of speech presence along with the audio samples.
Create a dsp.AudioFileReader System object™ to read a speech file.
afr = dsp.AudioFileReader('Counting-16-44p1-mono-15secs.wav');
fs = afr.SampleRate;
Chunk the audio into 20 ms frames with 75% overlap between successive frames. Convert the frame time in seconds to samples. Determine the hop size (the increment of new samples). In the audio file reader, set the samples per frame to the hop size. Create a default dsp.AsyncBuffer object to manage overlapping between audio frames.
frameSize = ceil(20e-3*fs);
overlapSize = ceil(0.75*frameSize);
hopSize = frameSize - overlapSize;
afr.SamplesPerFrame = hopSize;
inputBuffer = dsp.AsyncBuffer('Capacity',frameSize);
Create a voiceActivityDetector System object. Specify an FFT length of 1024.
VAD = voiceActivityDetector('FFTLength',1024);
Create a scope to plot the audio signal and corresponding probability of speech presence as detected by the voice activity detector. Create an audioDeviceWriter System object to play audio through your sound card.
scope = timescope('NumInputPorts',2, ... 'SampleRate',fs, ... 'TimeSpanSource','Property','TimeSpan',3, ... 'BufferLength',3*fs, ... 'YLimits',[-1.5,1.5], ... 'TimeSpanOverrunAction','Scroll', ... 'ShowLegend',true, ... 'ChannelNames',{'Audio','Probability of speech presence'}); player = audioDeviceWriter('SampleRate',fs);
Initialize a vector to hold the probability values.
pHold = ones(hopSize,1);
In an audio stream loop:
Read a hop worth of samples from the audio file and save the samples into the buffer.
Read a frame from the buffer with specified overlap from the previous frame.
Call the voice activity detector to get the probability of speech for the frame under analysis.
Set the last element of the probability vector to the new probability decision. Visualize the audio and speech presence probability using the time scope.
Play the audio through your sound card.
Set the probability vector to the most recent result for plotting in the next loop.
while ~isDone(afr) x = afr(); n = write(inputBuffer,x); overlappedInput = read(inputBuffer,frameSize,overlapSize); p = VAD(overlappedInput); pHold(end) = p; scope(x,pHold) player(x); pHold(:) = p; end

Release the player once the audio finishes playing.
release(player)
Create a dsp.AudioFileReader object to read in audio frame-by-frame.
fileReader = dsp.AudioFileReader("SingingAMajor-16-mono-18secs.ogg");Create a voiceActivityDetector object to detect the presence of voice in streaming audio.
VAD = voiceActivityDetector;
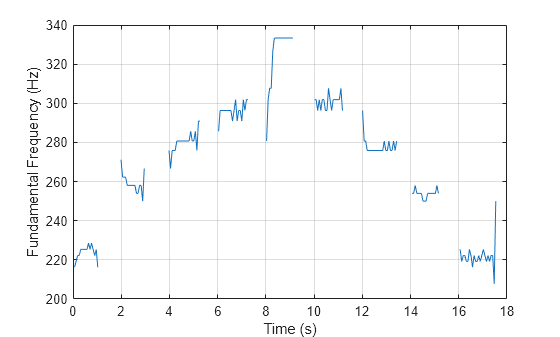
While there are unread samples, read from the file and determine the probability that the frame contains voice activity. If the frame contains voice activity, call pitch to estimate the fundamental frequency of the audio frame. If the frame does not contain voice activity, declare the fundamental frequency as NaN.
f0 = []; while ~isDone(fileReader) x = fileReader(); if VAD(x) > 0.99 decision = pitch(x,fileReader.SampleRate, ... WindowLength=size(x,1), ... OverlapLength=0, ... Range=[200,340]); else decision = NaN; end f0 = [f0;decision]; end
Plot the detected pitch contour over time.
t = linspace(0,(length(f0)*fileReader.SamplesPerFrame)/fileReader.SampleRate,length(f0)); plot(t,f0) ylabel("Fundamental Frequency (Hz)") xlabel("Time (s)") grid on
Algorithms
The voiceActivityDetector implements the algorithm described in [1].
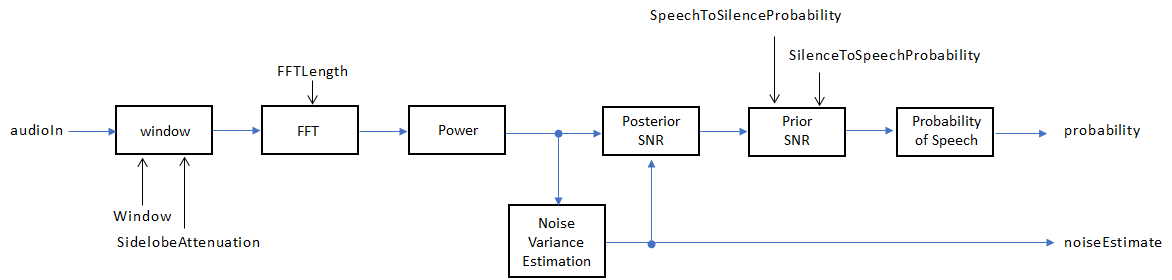
If InputDomain is specified as 'Time', the input
signal is windowed and then converted to the frequency domain according to the
Window, SidelobeAttenuation, and
FFTLength properties. If InputDomain is specified
as frequency, the input is assumed to be a windowed discrete time Fourier transform (DTFT) of
an audio signal. The signal is then converted to the power domain. Noise variance is estimated
according to [2]. The posterior and prior
SNR are estimated according to the Minimum Mean-Square Error (MMSE) formula described in [3]. A log likelihood ratio
test and Hidden Markov Model (HMM)-based hang-over scheme determine the probability that the
current frame contains speech, according to [1].
References
[1] Sohn, Jongseo., Nam Soo Kim, and Wonyong Sung. "A Statistical Model-Based Voice Activity Detection." Signal Processing Letters IEEE. Vol. 6, No. 1, 1999.
[2] Martin, R. "Noise Power Spectral Density Estimation Based on Optimal Smoothing and Minimum Statistics." IEEE Transactions on Speech and Audio Processing. Vol. 9, No. 5, 2001, pp. 504–512.
[3] Ephraim, Y., and D. Malah. "Speech Enhancement Using a Minimum Mean-Square Error Short-Time Spectral Amplitude Estimator." IEEE Transactions on Acoustics, Speech, and Signal Processing. Vol. 32, No. 6, 1984, pp. 1109–1121.
Extended Capabilities
Version History
Introduced in R2018a
See Also
audioFeatureExtractor | mfcc | pitch | cepstralCoefficients | Voice Activity
Detector