Navigating Climate Finance: Software Solutions for Climate Risk Management
Elre Oldewage, MathWorks
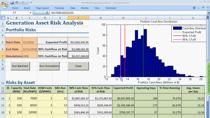
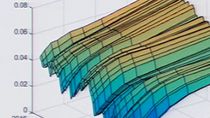
In the evolving landscape of climate finance, the need to incorporate climate impacts into risk management strategies presents significant challenges and opportunities. This presentation leverages empirical data and real-world experiences to explore the intricacies of managing climate-related financial risks through software applications. Explore workflows around geolocating physical assets, hazard identification, financial impact estimation, and the integration of climate risk into operational frameworks. By examining case studies, this talk demonstrates the pivotal role of software solutions in transparent, scalable, and reproduceable climate risk management.
Published: 22 Oct 2024
Related Products
Learn More
Featured Product