Getting Started with Video Classification Using Deep Learning
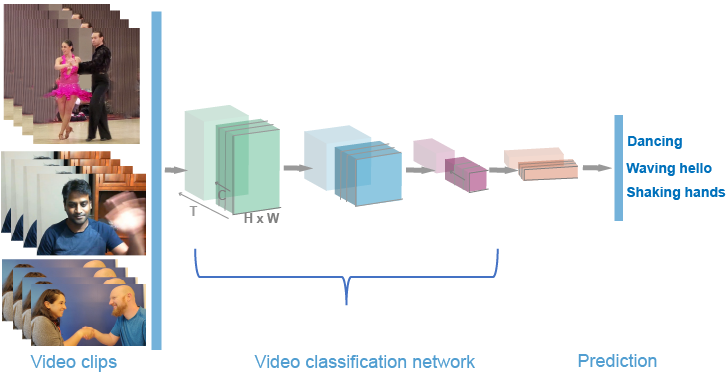
Video classification is similar to image classification, in that the algorithm uses feature extractors, such as convolutional neural networks (CNNs), to extract feature descriptors from a sequence of images and then classify them into categories. Video classification using deep learning provides a means to analyze, classify, and track activity contained in visual data sources, such as a video stream. Video classification has many applications, such as human activity recognition, gesture recognition, anomaly detection, and surveillance.
Video classification methodology includes these steps:
Prepare training data
Choose a video classifier
Train and evaluate the classifier
Use the classifier to process video data
You can train a classifier using a video classifier pretrained on a large activity recognition video data set, such as the Kinetics-400 Human Action Dataset, which is a large-scale and high-quality data set collection. Start by providing the video classifier with labeled video or video clips. Then, using a deep learning video classifier that consists of convolution neural networks that match the nature of the video input, you can predict and classify the videos. Ideally, your workflow should include the evaluation of your classifier. Finally, you can use the classifier to classify activity in a collection of videos or a streaming video from a webcam.
Computer Vision Toolbox™ provides the slow and fast pathway (SlowFast), ResNet with (2+1)D convolutions, and two-stream Inflated-3D techniques for training a classifier of video classification.
Create Training Data for Video Classification
To train a classifier network, you need a collection of videos and its corresponding
collection of scene labels. A scene label is a label applied to a time range in a video. For
example, you could label a range of frames "jumping".
You can use the Video Labeler or Ground Truth Labeler (Automated Driving Toolbox) to interactively label ground truth data in a video, image sequence, or custom data source with scene labels. For a summary all labelers, see Choose an App to Label Ground Truth Data.
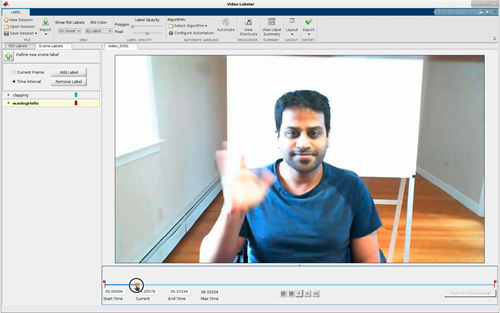
The labeler apps export labeled data into MAT files that contain groundTruth objects. For an example showing how to extract training data from
ground truth objects, see Extract Training Data for Video Classification.
Augment and Preprocess Data
Data augmentation provides a way to use limited data sets for training. Minor changes,
such as translating, cropping, or transforming an image, provide new, distinct, and unique
images that you can use to train a robust video classifier. Datastores are a convenient way
to read and augment collections of data. Use the fileDatastore function with a read function that uses the
VideoReader to read video files, to create
datastores for videos and labeled scene label data. For an example that augments and
preprocesses data, see Gesture Recognition using Videos and Deep Learning.
To learn how to augment and preprocess data, see Perform Additional Image Processing Operations Using Built-In Datastores (Deep Learning Toolbox) and Datastores for Deep Learning (Deep Learning Toolbox).
Create Video Classifier
Choose one of the listed video classifier objects to create deep learning classification networks using models pretrained models using the Kinetics-400 data set (which contains 400 class labels):
The
slowFastVideoClassifiermodel is pretrained on the Kinetics-400 data set which contains the residual network ResNet-50 model as the backbone architecture with slow and fast pathways. This functionality requires the Computer Vision Toolbox Model for SlowFast Video Classification.The
r2plus1dVideoClassifiermodel is pretrained on the Kinetics-400 data set which contains 18 spatio-temporal (ST) residual layers. This functionality requires the Computer Vision Toolbox Model for R(2+1)D Video Classification.The
inflated3dVideoClassifiermodel contains two subnetworks: the video network and the optical flow network. These networks are trained on the Kinetics-400 data set with RGB data and optical flow data, respectively. This functionality requires the Computer Vision Toolbox Model for Inflated-3D Video Classification.
The table provides a comparison of these deep learning supported classifiers:
Model | Data Sources | Classifier Model Size (Pretrained on Kinetics-400 Dataset) | GPU Support | Multiple Class Support | Description |
|---|---|---|---|---|---|
SlowFast | Video data | 124 MB | Yes | Yes |
|
R(2+1)D | Video data | 112 MB | Yes | Yes |
|
Inflated-3D |
| 91 MB | Yes | Yes |
|
This table shows sample code you can use to create a video classifier using each of the listed video classifiers:
| Video Classifier | Sample Creation Code |
|---|---|
SlowFast |
inputSize = [112 112 64 3]; classes = ["wavingHello","clapping"]; sf = slowFastVideoClassifier("resnet50-3d",classes,InputSize=inputSize) |
R(2+1)D |
inputSize = [112 112 64 3]; classes = ["wavingHello","clapping"]; rd = r2plus1dVideoClassifier("resnet-3d-18",classes,InputSize=inputSize) |
Inflated 3-D |
inputSize = [112 112 64 3]; classes = ["wavingHello","clapping"]; i3d = inflated3dVideoClassifier("googlenet-video-flow",classes,InputSize=inputSize) |
Train Video Classifier and Evaluate Results
To learn how to train and evaluate the results for the listed video classifiers, see these examples:
Gesture Recognition using Videos and Deep Learning — Train and evaluate a SlowFast video classifier
Human Activity Recognition Using R(2+1)D Video Classification — Train and evaluate an R(2+1)D video classifier
Activity Recognition from Video and Optical Flow Data Using Deep Learning — Train and evaluate a two-stream Inflated-3D video classifier
Classify Using Deep Learning Video Classifiers
To learn how to classify videos using a video classifier, see these examples:
See Also
Apps
- Video Labeler | Ground Truth Labeler (Automated Driving Toolbox)
Topics
- Classify Videos Using Deep Learning (Deep Learning Toolbox)
- Get Started with the Video Labeler