Reinforcement Learning Workflow
The general workflow for training an agent using reinforcement learning includes the following steps.
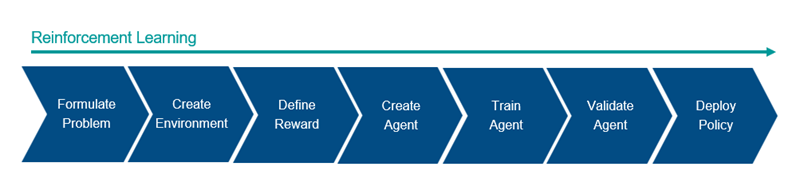
Formulate problem — Define the task for the agent to learn, including how the agent interacts with the environment and any primary and secondary goals the agent must achieve.
Create environment — Define the environment within which the agent operates, including the interface between agent and environment and the environment dynamic model. For more information, see Reinforcement Learning Environments.
Define reward — Specify the reward signal that the agent uses to measure its performance against the task goals and how to calculate this signal from the environment. For more information, see Define Observation and Reward Signals in Custom Environments.
Create agent — Create the agent. You can create a default built-in agent, or a built-in agent with custom actor and critic objects. For more information, see Create Actors, Critics, and Policy Objects and Reinforcement Learning Agents.
Train agent — Train the agent approximators using the defined environment, reward, and agent learning algorithm. For more information, see Train Reinforcement Learning Agents.
Simulate agent — Evaluate the performance of the trained agent by simulating the agent and environment together. For more information, see Train Reinforcement Learning Agents.
Deploy policy — Deploy the trained policy approximator using, for example, generated GPU code. For more information, see Generate Code from Trained Reinforcement Learning Policies.
Training an agent using reinforcement learning is an iterative process. Decisions and results in later stages can require you to return to an earlier stage in the learning workflow. For example, if the training process does not converge to an optimal policy within a reasonable amount of time, you might have to update some of the following before retraining the agent:
Training settings
Learning algorithm configuration
Policy and value function (actor and critic) approximators
Reward signal definition
Action and observation signals
Environment dynamics
See Also
Topics
- Train Reinforcement Learning Agent in MDP Environment
- Train Reinforcement Learning Agent in Basic Grid World
- Control Water Level in a Tank Using a DDPG Agent
- What Is Reinforcement Learning?
- Reinforcement Learning Environments
- Reinforcement Learning Agents
- Train Reinforcement Learning Agents
- Reinforcement Learning for Control Systems Applications