infer
Infer residuals of univariate regression model with ARIMA time series errors
Syntax
Description
Tbl2 = infer(Mdl,Tbl1)Tbl2 containing paths of residuals,
unconditional disturbances, innovation variances inferred from the model
Mdl and the response data in the input table or timetable
Tbl1. (since R2023b)
infer selects the response variable named in
Mdl.SeriesName or the sole variable in Tbl1. To
select a different response variable in Tbl1 to infer residuals,
unconditional disturbances, and innovation variances, use the
ResponseVariable name-value argument.
[___] = infer(___,
specifies options using one or more name-value arguments in
addition to any of the input argument combinations in previous syntaxes.
Name=Value)infer returns the output argument combination for the
corresponding input arguments. For example, infer(Mdl,Y,U0=u0,X=Pred) infers residuals
from the numeric vector of response data Y with respect to the
regression model with ARIMA errors Mdl, and specifies the numeric
vector of presample regression model residual data u0 to initialize the
model and the predictor data Pred for the regression component.
Examples
Infer error model residuals from a simulated path of responses from the following regression model with ARMA(2,1) errors:
where is Gaussian with variance 0.1. Assume the predictors are standard Gaussian random variables. Provide data as numeric arrays.
Create the regression model with ARIMA errors. Simulate responses from the model and two predictor series.
Mdl = regARIMA(Intercept=0,AR={0.5 -0.8},MA=-0.5, ...
Beta=[0.1; -0.2],Variance=0.1);
rng(1,"twister"); % For reproducibility
Pred = randn(100,2);
y = simulate(Mdl,100,X=Pred);Infer and plot the error model residuals. By default, infer backcasts for the necessary presample unconditional disturbances and sets necessary presample error model residuals to zero.
e = infer(Mdl,y,X=Pred);
figure
plot(e)
title("Inferred Residuals")
e is a 100-by-1 vector of error model residuals, associated with error model innovations .
Since R2023b
Fit a regression model with ARMA(1,1) errors by regressing the US gross domestic product (GDP) growth rate onto consumer price index (CPI) quarterly changes. Examine the error model and regression residuals. Supply a timetable of data and specify the series for the fit.
Load and Transform Data
Load the US macroeconomic data set. Compute the series of GDP quarterly growth rates and CPI quarterly changes.
load Data_USEconModel DTT = price2ret(DataTimeTable,DataVariables="GDP"); DTT.GDPRate = 100*DTT.GDP; DTT.CPIDel = diff(DataTimeTable.CPIAUCSL); T = height(DTT)
T = 248
figure tiledlayout(2,1) nexttile plot(DTT.Time,DTT.GDPRate) title("GDP Rate") ylabel("Percent Growth") nexttile plot(DTT.Time,DTT.CPIDel) title("Index")
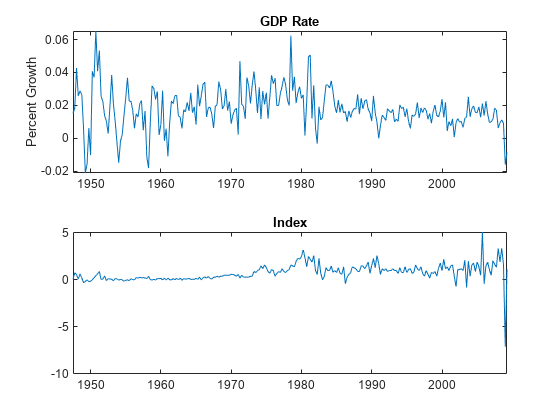
The series appear stationary, albeit heteroscedastic.
Prepare Timetable for Estimation
When you plan to supply a timetable, you must ensure it has all the following characteristics:
The selected response variable is numeric and does not contain any missing values.
The timestamps in the
Timevariable are regular, and they are ascending or descending.
Remove all missing values from the timetable.
DTT = rmmissing(DTT); T_DTT = height(DTT)
T_DTT = 248
Because each sample time has an observation for all variables, rmmissing does not remove any observations.
Determine whether the sampling timestamps have a regular frequency and are sorted.
areTimestampsRegular = isregular(DTT,"quarters")areTimestampsRegular = logical
0
areTimestampsSorted = issorted(DTT.Time)
areTimestampsSorted = logical
1
areTimestampsRegular = 0 indicates that the timestamps of DTT are irregular. areTimestampsSorted = 1 indicates that the timestamps are sorted. Macroeconomic series in this example are timestamped at the end of the month. This quality induces an irregularly measured series.
Remedy the time irregularity by shifting all dates to the first day of the quarter.
dt = DTT.Time; dt = dateshift(dt,"start","quarter"); DTT.Time = dt; areTimestampsRegular = isregular(DTT,"quarters")
areTimestampsRegular = logical
1
DTT is regular.
Create Model Template for Estimation
Suppose that a regression model of CPI quarterly changes onto the GDP rate, with ARMA(1,1) errors, is appropriate.
Create a model template for a regression model with ARMA(1,1) errors template. Specify the response variable name.
Mdl = regARIMA(1,0,1);
Mdl.SeriesName = "GDPRate";Mdl is a partially specified regARIMA object.
Fit Model to Data
Fit a regression model with ARMA(1,1) errors to the data. Specify the entire series GDP rate and CPI quarterly changes series, and specify the predictor variable name.
EstMdl = estimate(Mdl,DTT,PredictorVariables="CPIDel");
Regression with ARMA(1,1) Error Model (Gaussian Distribution):
Value StandardError TStatistic PValue
________ _____________ __________ __________
Intercept 0.0162 0.0016077 10.077 6.9996e-24
AR{1} 0.60515 0.089912 6.7305 1.6905e-11
MA{1} -0.16221 0.11051 -1.4678 0.14216
Beta(1) 0.002221 0.00077691 2.8587 0.0042532
Variance 0.000113 7.2753e-06 15.533 2.0837e-54
EstMdl is a fully specified, estimated regARIMA object. By default, estimate backcasts for the required Mdl.P = 1 presample regression model residual and sets the required Mdl.Q = 1 presample error model residual to 0.
Examine Residuals
Infer a timetable of error model and regression residuals for all observations. Specify the predictor variable name.
Tbl2 = infer(EstMdl,DTT,PredictorVariables="CPIDel")Tbl2=248×6 timetable
Time Interval GDP GDPRate CPIDel GDPRate_ErrorResidual GDPRate_RegressionResidual
_____ ________ ___________ _________ ______ _____________________ __________________________
Q2-47 91 0.00015183 0.015183 0.08 -0.0007572 -0.0011947
Q3-47 92 0.00018374 0.018374 0.76 0.0010863 0.00048617
Q4-47 92 0.000427 0.0427 0.57 0.025116 0.025234
Q1-48 91 0.00025617 0.025617 0.09 -0.0019795 0.0092168
Q2-48 91 0.00028739 0.028739 0.65 0.005197 0.011096
Q3-48 92 0.00026512 0.026512 0.21 0.0039745 0.0098461
Q4-48 92 5.1468e-05 0.0051468 -0.31 -0.015678 -0.010365
Q1-49 90 -0.00021196 -0.021196 -0.14 -0.033356 -0.037085
Q2-49 91 -0.00015576 -0.015576 0.01 -0.014767 -0.031798
Q3-49 92 6.1077e-05 0.0061077 -0.17 0.0071327 -0.0097147
Q4-49 91 -0.00010311 -0.010311 -0.14 -0.019164 -0.0262
Q1-50 91 0.00040675 0.040675 0.03 0.037154 0.024408
Q2-50 91 0.00036908 0.036908 0.24 0.011432 0.020175
Q3-50 91 0.00065211 0.065211 0.46 0.037635 0.04799
Q4-50 91 0.00040718 0.040718 0.64 0.00016008 0.023097
Q1-51 91 0.00053382 0.053382 0.9 0.021232 0.035183
⋮
Tbl2 is a 248-by-6 timetable containing the error model residuals GDPRate_ErrorResidual, regression residuals GDPRate_RegressionResidual, and all variables in DTT.
Separately plot the inferred error model and regression residuals.
Tbl2.GDPRate_Fitted = Tbl2.GDPRate - Tbl2.GDPRate_RegressionResidual; figure h = tiledlayout(2,2); title(h,"Error Model Residuals") nexttile plot(Tbl2.Time,Tbl2.GDPRate_ErrorResidual,'b',Tbl2.Time([1 end]),[0 0],'--r') title("Case Order") nexttile histogram(Tbl2.GDPRate_ErrorResidual) title("Histogram") nexttile plot(Tbl2.GDPRate_ErrorResidual(1:end-1),Tbl2.GDPRate_ErrorResidual(2:end),'o') title("e_{t-1} versus e_t") nexttile plot(Tbl2.GDPRate_Fitted,Tbl2.GDPRate_ErrorResidual,'o') title("Fitted versus e_t")

figure h = tiledlayout(2,2); title(h,"Regression Residuals") nexttile plot(Tbl2.Time,Tbl2.GDPRate_RegressionResidual,'b',Tbl2.Time([1 end]),[0 0],'--r') title("Case Order") nexttile histogram(Tbl2.GDPRate_RegressionResidual) title("Histogram") nexttile plot(Tbl2.GDPRate_RegressionResidual(1:end-1),Tbl2.GDPRate_RegressionResidual(2:end),'o') title("e_{t-1} versus e_t") nexttile plot(Tbl2.GDPRate_Fitted,Tbl2.GDPRate_RegressionResidual,'o') title("Fitted versus e_t")
Fit this regression model with ARMA(2,1) errors to simulated data:
where is Gaussian with variance 0.1. Compare the fit to an intercept-only regression model by conducting a likelihood ratio test. Provide response and predictor data in vectors.
Simulate Data
Specify the regression model ARMA(2,1) errors. Simulate responses from the model, and simulate two predictor series from the standard Gaussian distribution.
Mdl0 = regARIMA(Intercept=1,AR={0.5 -0.8},MA=-0.5, ...
Beta=[0.1; -0.2],Variance=0.1);
rng(1,"twister") % For reproducibility
Pred = randn(100,2);
y = simulate(Mdl0,100,X=Pred);y is a 100-by-1 random response path simulated from Mdl.
Fit Unrestricted Model
Create an unrestricted model template of a regression model with ARMA(2,1) errors for estimation.
Mdl = regARIMA(2,0,1)
Mdl =
regARIMA with properties:
Description: "ARMA(2,1) Error Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
Intercept: NaN
Beta: [1×0]
P: 2
Q: 1
AR: {NaN NaN} at lags [1 2]
SAR: {}
MA: {NaN} at lag [1]
SMA: {}
Variance: NaN
The AR coefficients, MA coefficients, and the innovation variance are NaN values. estimate estimates those parameters. When Beta is an empty array, estimate determines the number of regression coefficients to estimate.
Fit the unrestricted model to the data. Specify the predictor data.
EstMdlUR = estimate(Mdl,y,X=Pred);
Regression with ARMA(2,1) Error Model (Gaussian Distribution):
Value StandardError TStatistic PValue
________ _____________ __________ __________
Intercept 1.0167 0.010154 100.13 0
AR{1} 0.64995 0.093794 6.9295 4.2226e-12
AR{2} -0.69174 0.082575 -8.3771 5.4247e-17
MA{1} -0.64508 0.11055 -5.835 5.3796e-09
Beta(1) 0.10866 0.020965 5.183 2.1835e-07
Beta(2) -0.20979 0.022824 -9.1917 3.8679e-20
Variance 0.073117 0.008716 8.3888 4.9121e-17
EstMdlUR is a fully specified regARIMA object representing the estimated unrestricted regression model with ARIMA errors.
Fit Restricted Model
The restricted model contains the same error model, but the regression model contains only an intercept. That is, the restricted model imposes two restrictions on the unrestricted model: .
Fit the restricted model to the data.
EstMdlR = estimate(Mdl,y);
ARMA(2,1) Error Model (Gaussian Distribution):
Value StandardError TStatistic PValue
________ _____________ __________ __________
Intercept 1.0176 0.024905 40.859 0
AR{1} 0.51541 0.18536 2.7805 0.0054271
AR{2} -0.53359 0.10949 -4.8735 1.0963e-06
MA{1} -0.34923 0.19423 -1.798 0.07218
Variance 0.1445 0.020214 7.1486 8.7671e-13
EstMdlR is a fully specified regARIMA object representing the estimated restricted regression model with ARIMA errors.
Compute Residuals and Loglikelihoods
Compute the residual series and loglikelihoods for the estimated models.
[eUR,uUR,~,logLUR] = infer(EstMdlUR,y,X=Pred); [eR,uR,~,logLR] = infer(EstMdlR,y);
eUR and uUR are 100-by-1 vectors containing the error model and regression residuals from the unrestricted estimation. loglUR is the corresponding loglikelihood.
eR and uR are 100-by-1 vectors containing the error model and regression residuals from the restricted estimation. loglR is the corresponding loglikelihood.
Conduct Likelihood Ratio Test
The likelihood ratio test requires the optimized loglikelihoods of the unrestricted and restricted models, and it requires the number of model restrictions (degrees of freedom).
Conduct a likelihood ratio test to determine which model has the better fit to the data.
dof = 2; [h,p] = lratiotest(logLUR,logLR,dof)
h = logical
1
p = 1.6653e-15
The -value is close to zero, which suggests that there is strong evidence to reject the null hypothesis that the data fits the restricted model better than the unrestricted model.
Input Arguments
Name-Value Arguments
Output Arguments
References
[1] Box, George E. P., Gwilym M. Jenkins, and Gregory C. Reinsel. Time Series Analysis: Forecasting and Control. 3rd ed. Englewood Cliffs, NJ: Prentice Hall, 1994.
[2] Davidson, R., and J. G. MacKinnon. Econometric Theory and Methods. Oxford, UK: Oxford University Press, 2004.
[3] Enders, Walter. Applied Econometric Time Series. Hoboken, NJ: John Wiley & Sons, Inc., 1995.
[4] Hamilton, James D. Time Series Analysis. Princeton, NJ: Princeton University Press, 1994.
[6] Tsay, R. S. Analysis of Financial Time Series. 2nd ed. Hoboken, NJ: John Wiley & Sons, Inc., 2005.