dsp.MovingRMS
Moving root mean square (RMS)
Description
The dsp.MovingRMS
System object™ computes the moving root mean square (RMS) of the input signal along each
channel, independently over time. The object uses either the sliding window method or the
exponential weighting method to compute the moving RMS. In the sliding window method, a window
of specified length is moved over the data, sample by sample, and the RMS is computed over the
data in the window. In the exponential weighting method, the object squares the data samples,
multiplies them with a set of weighting factors, and sums the weighed data. The object then
computes the RMS by taking the square root of the sum. For more details on these methods, see
Algorithms.
To compute the moving RMS of the input:
Create the
dsp.MovingRMSobject and set its properties.Call the object with arguments, as if it were a function.
To learn more about how System objects work, see What Are System Objects?
Creation
Syntax
Description
movRMS = dsp.MovingRMSmovRMS, using the default properties.
movRMS = dsp.MovingRMS(Len)WindowLength property to Len.
MovRMS = dsp.MovingRMS(Len,Overlap)WindowLength property to Len and the
OverlapLength property to Overlap.
movRMS = dsp.MovingRMS(PropertyName=Value)Name,Value pairs. Unspecified
properties have default values.
Example: movRMS = dsp.MovingRMS('Method','Exponential
weighting','ForgettingFactor',0.9);
Properties
Usage
Syntax
Description
Input Arguments
Output Arguments
Object Functions
To use an object function, specify the
System object as the first input argument. For
example, to release system resources of a System object named obj, use
this syntax:
release(obj)
Examples
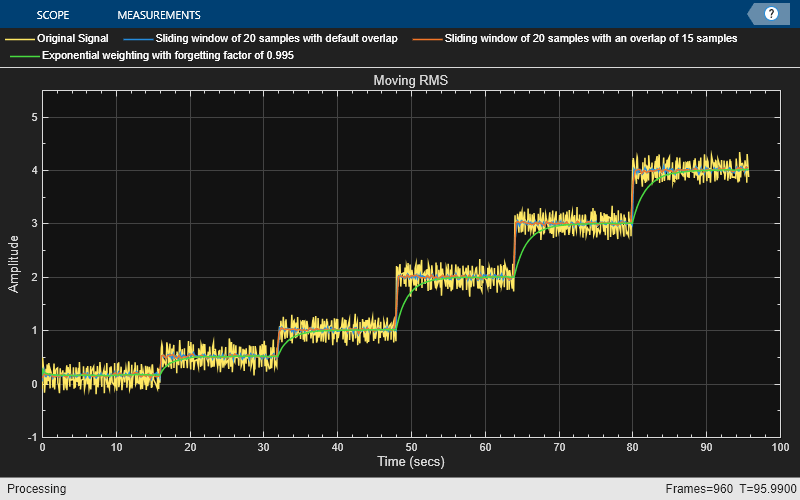
Compute the moving RMS of a noisy square wave signal with varying amplitude using the dsp.MovingRMS object.
Initialization
Set up movrmsWin, movrmsWin_overlap, and movrmsExp objects. movrmsWin uses the sliding window method with a window length of 20 samples and a default overlap length of 19 samples, which is one sample less than the specified window length. movrmsWin_overlap uses a window length of 20 samples and an overlap length of 15 samples. movrmsExp uses the exponentially weighting method with a forgetting factor of 0.995.
Create a time scope for viewing the output.
FrameLength = 10; Fs = 100; movrmsWin = dsp.MovingRMS(20); movrmsWin_overlap = dsp.MovingRMS(20,15); movrmsExp = dsp.MovingRMS('Method','Exponential weighting',... 'ForgettingFactor',0.995); scope = timescope('SampleRate',[Fs,Fs,Fs/(20-15),Fs],... 'TimeSpanOverrunAction','Scroll',... 'TimeSpanSource','Property',... 'TimeSpan',100,... 'ShowGrid',true,... 'YLimits',[-1.0 5.5]); title = 'Moving RMS'; scope.Title = title; scope.ChannelNames = {'Original Signal',... 'Sliding window of 20 samples with default overlap',... 'Sliding window of 20 samples with an overlap of 15 samples',... 'Exponential weighting with forgetting factor of 0.995'};
Compute the RMS
Generate a noisy square wave signal. Vary the amplitude of the square wave after a given number of frames. Apply the sliding window method and the exponential weighting method to this signal. View the output in the time scope.
count = 1; Vect = [1/8 1/2 1 2 3 4]; for index = 1:length(Vect) V = Vect(index); for i = 1:160 x = V + 0.1 * randn(FrameLength,1); y1 = movrmsWin(x); y2 = movrmsWin_overlap(x); y3 = movrmsExp(x); scope(x,y1,y2,y3); end end
Algorithms
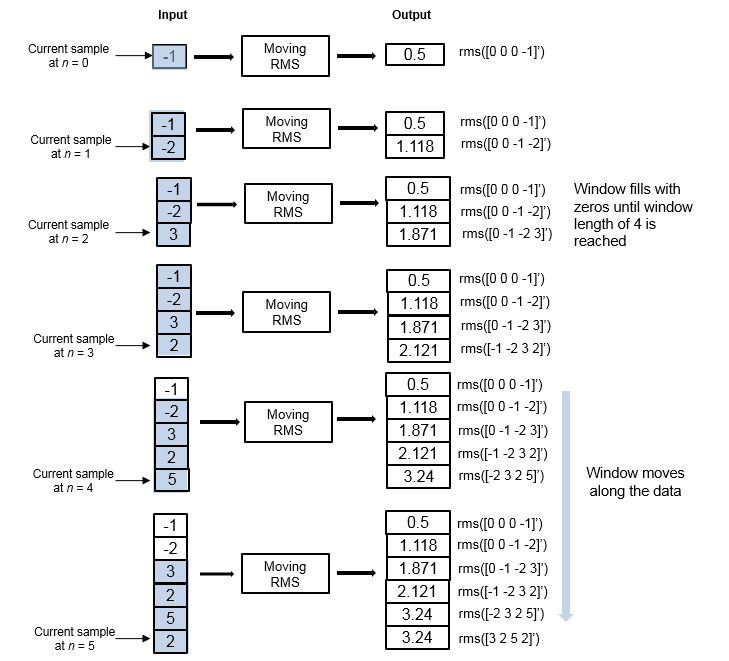
In the sliding window method, the output for each input sample is the RMS of the current sample and Len – 1 previous samples. Len is the length of the window in samples. To compute the first output sample, the algorithm waits until it receives the hop size number of input samples. Hop size is defined as window length – overlap length. Remaining samples in the window are considered to be zero. As an example, if the window length is 5 and the overlap length is 2, then the algorithm waits until it receives 3 samples of input to compute the first sample of the output. After generating the first output, it generates the subsequent output samples for every hop size number of input samples.
When you do not specify the window length, the algorithm chooses an infinite window length. In this mode, the output is the moving RMS of the current sample and all the previous samples in the channel.
Consider an example of computing the moving RMS of a streaming input data using the sliding window method. The algorithm uses a window length of 4 and an overlap length of 3. With each input sample that comes in, the window of length 4 moves along the data.
In the exponential weighting method, the moving RMS is computed recursively using these formulas:
— Moving RMS at the current sample
— Square of the current input data sample
— Moving RMS at the previous sample
λ — Forgetting factor
— Weighting factor applied to the current data sample
— Effect of the previous data on the RMS
For the first sample, where N = 1, the algorithm chooses = 1. For the next sample, the weighting factor is updated and used to compute the RMS, as per the recursive equation. As the age of the data increases, the magnitude of the weighting factor decreases exponentially and never reaches zero. In other words, the recent data has more influence on the current RMS than the older data.
The value of the forgetting factor determines the rate of change of the weighting factors. A forgetting factor of 0.9 gives more weight to the older data than does a forgetting factor of 0.1. A forgetting factor of 1.0 indicates infinite memory. All the previous samples are given an equal weight.
Here is an example of computing the moving RMS using the exponential weighting method. The forgetting factor is 0.9.

References
[1] Bodenham, Dean. “Adaptive Filtering and Change Detection for Streaming Data.” PH.D. Thesis. Imperial College, London, 2012.
Extended Capabilities
Version History
Introduced in R2016bSee Also
Objects
dsp.MovingAverage|dsp.MovingMaximum|dsp.MovingMinimum|dsp.MovingStandardDeviation|dsp.MovingVariance|dsp.MedianFilter