Deep Network Quantizer
Quantize deep neural network to 8-bit scaled integer data types
Description
Add-On Required: This feature requires the Deep Learning Toolbox Model Compression Library add-on.
Use the Deep Network Quantizer app to reduce the memory requirement of a deep neural network by quantizing weights, biases, and activations of layers to 8-bit scaled integer data types. Using this app, you can:
Visualize the dynamic ranges of convolution layers in a deep neural network.
Select individual network layers to quantize.
Assess the performance of a quantized network.
Generate GPU code to deploy the quantized network using GPU Coder™.
Generate HDL code to deploy the quantized network to an FPGA using Deep Learning HDL Toolbox™.
Generate C++ code to deploy the quantized network to an ARM Cortex-A microcontroller using MATLAB® Coder™.
Generate a simulatable quantized network that you can explore in MATLAB without generating code or deploying to hardware.
This app requires the Deep Learning Toolbox Model Compression Library. To learn about the products required to quantize a deep neural network, see Quantization Workflow System Requirements.
Open the Deep Network Quantizer App
MATLAB command prompt: Enter
deepNetworkQuantizer.MATLAB toolstrip: On the Apps tab, under Machine Learning and Deep Learning, click the app icon.
Examples
To explore the behavior of a neural network with quantized layers, use the Deep Network Quantizer app. This example quantizes the learnable parameters and activations of layers in the squeezenet neural network after retraining the network to classify new images.
This example uses a dlnetwork with the GPU execution environment.
Load the network to quantize into the base workspace.
load squeezedlnetmerch
netnet =
dlnetwork with properties:
Layers: [67×1 nnet.cnn.layer.Layer]
Connections: [74×2 table]
Learnables: [52×3 table]
State: [0×3 table]
InputNames: {'data'}
OutputNames: {'prob'}
Initialized: 1
View summary with summary.
Define calibration and validation data.
The app uses calibration data to exercise the network and collect the dynamic ranges of the weights, biases. and activations for layers of the network. For the best quantization results, the calibration data must be representative of inputs to the network.
The app uses the validation data to test the network after quantization to understand the effects of the limited range and precision of the quantized learnable parameters of the layers in the network.
In this example, use the images in the MerchData data set. Split the data into calibration and validation data sets.
unzip('MerchData.zip'); imds = imageDatastore('MerchData', ... 'IncludeSubfolders',true, ... 'LabelSource','foldernames'); [calData, valData] = splitEachLabel(imds,0.7,'randomized');
At the MATLAB command prompt, open the app.
deepNetworkQuantizer
In the app, click New and select Quantize a network.
In the dialog, select the execution environment and the network to quantize from the base workspace. For this example, select a GPU execution environment and net - dlnetwork. For more information on selecting an execution environment, see Quantization of Deep Neural Networks.
Select the Prepare network for quantization option. Network preparation modifies your neural network to improve performance and avoid error conditions in the quantization workflow. For more information, see prepareNetwork.

Click OK. The app displays the layer graph of the selected network.
In the Calibrate section of the toolstrip, under Calibration Data, select the ImageDatastore object from the base workspace containing the calibration data, calData. Click Calibrate.
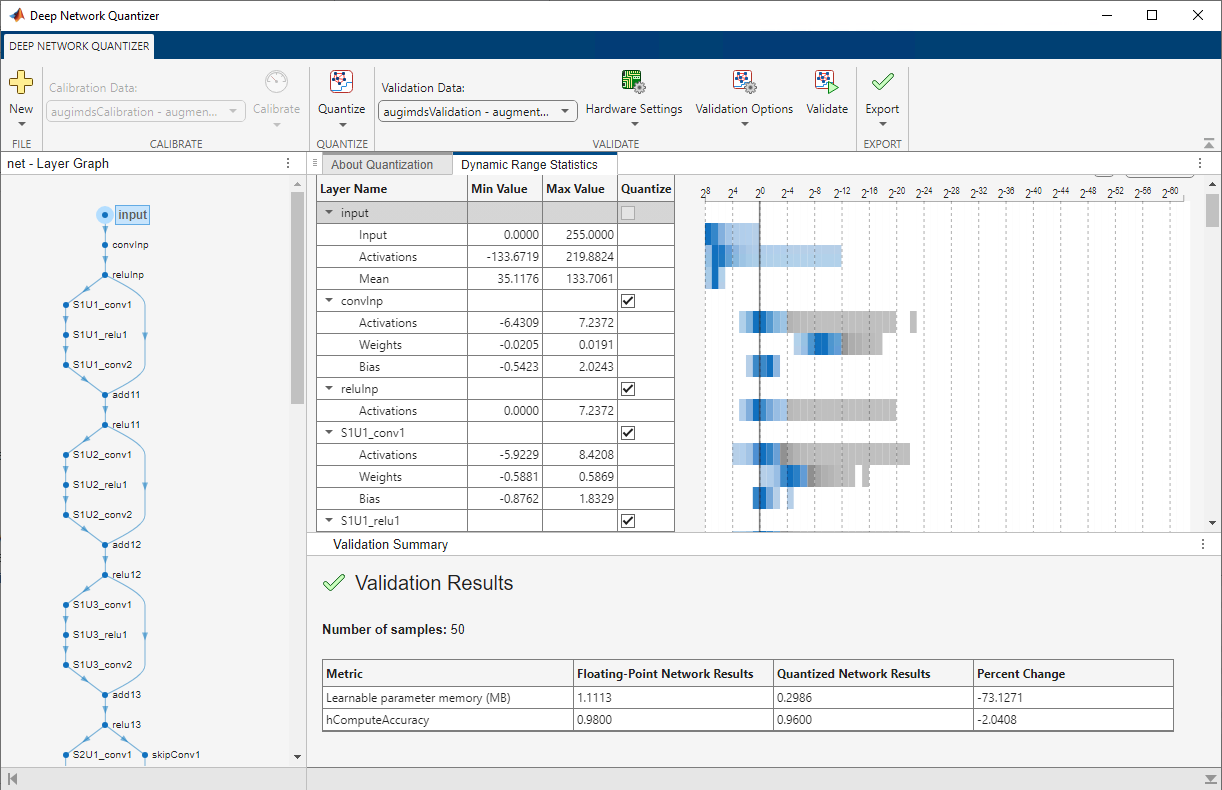
The Deep Network Quantizer uses the calibration data to exercise the network and collect range information for the learnable parameters in the network layers.
When the calibration is complete, the app displays a table containing the weights, biases, and activations for layers of the network and their minimum and maximum values during the calibration. To the right of the table, the app displays histograms of the dynamic ranges of the parameters.

In the Quantize section of the toolstrip, under Quantize, select the MinMax exponent scheme. Click Quantize.
The Deep Network Quantizer quantizes the weights, activations, and biases of layers in the network to scaled 8-bit integer data types. The app updates the histogram of the dynamic ranges of the parameters. The gray regions of the histograms indicate data that cannot be represented by the quantized representation. For more information on how to interpret these histograms, see Data Types and Scaling for Quantization of Deep Neural Networks.
In the Quantize column of the table, indicate whether to quantize the learnable parameters in the layer. Layers that are not quantized remain in single precision after quantization.

In the Validate section of the toolstrip, under Validation Data, select the ImageDatastore object from the base workspace containing the validation data, valData.
Define a custom metric function, hComputeModelAccuracy. Save this custom metric function in a local file.
function accuracy = hComputeModelAccuracy(predictionScores, ~, dataStore) %% Computes model-level accuracy statistics classNames = categories(dataStore.Labels); predictedLabels = scores2label(predictionScores,classNames); accuracy = mean(squeeze(predictedLabels) == dataStore.Labels); end
In the Validate section of the toolstrip, under Validation Options, enter the name of the custom metric function, hComputeModelAccuracy. Select Add to add hComputeModelAccuracy to the list of metric functions available in the app. Select hComputeModelAccuracy as the metric function to use.
The custom metric function must be on the path. If the metric function is not on the path, this step causes an error.

Click Validate. The app uses the validation data to exercise the network.
When the validation is complete, the app displays the results of the validation, including:
Metric function used for validation
Result of the metric function before and after quantization
Memory requirement of the network before and after quantization (MB)

The app displays only scalar values in the validation results table. To view the validation results for a custom metric function with nonscalar output, export the dlquantizer object as described below, then validate the dlquantizer object using the validate function in the MATLAB command window.
If the performance of the quantized network is not satisfactory, you can choose to not quantize some layers by clearing the layer in the table. You can also explore the effects of choosing a different exponent selection scheme for quantization in the Quantize menu. To see the effects of these changes, quantize and validate the network again.
After calibrating and quantizing the network, you can choose to export the quantized network or the dlquantizer object. Select the Export button. In the drop-down list, select from the following options:
Export Quantized Network — Add the quantized network to the base workspace. This option exports a simulatable quantized network that you can explore in MATLAB without deploying to hardware.
Export Quantizer — Add the
dlquantizerobject to the base workspace. You can save thedlquantizerobject and use it for further exploration in the Deep Network Quantizer app or at the command line, or use it to generate code for your target hardware.Generate Code — Open the GPU Coder app and generate GPU code from the quantized neural network. Generating GPU code requires a GPU Coder™ license.
To explore the behavior of a neural network with quantized convolution layers, use the Deep Network Quantizer app. This example quantizes the learnable parameters and activations of layers in the squeezenet neural network after retraining the network to classify new images.
This example uses a dlnetwork with the CPU execution environment.
Load the network to quantize into the base workspace.
load squeezedlnetmerch
netnet =
dlnetwork with properties:
Layers: [67×1 nnet.cnn.layer.Layer]
Connections: [74×2 table]
Learnables: [52×3 table]
State: [0×3 table]
InputNames: {'data'}
OutputNames: {'prob'}
Initialized: 1
View summary with summary.
Define calibration and validation data.
The app uses calibration data to exercise the network and collect the dynamic ranges of the weights, biases. and activations for layers of the network. For the best quantization results, the calibration data must be representative of inputs to the network.
The app uses the validation data to test the network after quantization to understand the effects of the limited range and precision of the quantized learnable parameters of the layers in the network.
In this example, use the images in the MerchData data set. Split the data into calibration and validation data sets.
unzip('MerchData.zip'); imds = imageDatastore('MerchData', ... 'IncludeSubfolders',true, ... 'LabelSource','foldernames'); [calData, valData] = splitEachLabel(imds, 0.7, 'randomized');
At the MATLAB command prompt, open the app.
deepNetworkQuantizer
In the app, click New and select Quantize a network.
In the dialog, select the execution environment and the network to quantize from the base workspace. For this example, select a CPU execution environment and net - dlnetwork. For more information on selecting an execution environment, see Quantization of Deep Neural Networks.
Select the Prepare network for quantization option. Network preparation modifies your neural network to improve performance and avoid error conditions in the quantization workflow. For more information, see prepareNetwork.

Click OK. The app displays the layer graph of the selected network.
In the Calibrate section of the toolstrip, under Calibration Data, select the ImageDatastore object from the base workspace containing the calibration data, calData. Click Calibrate.
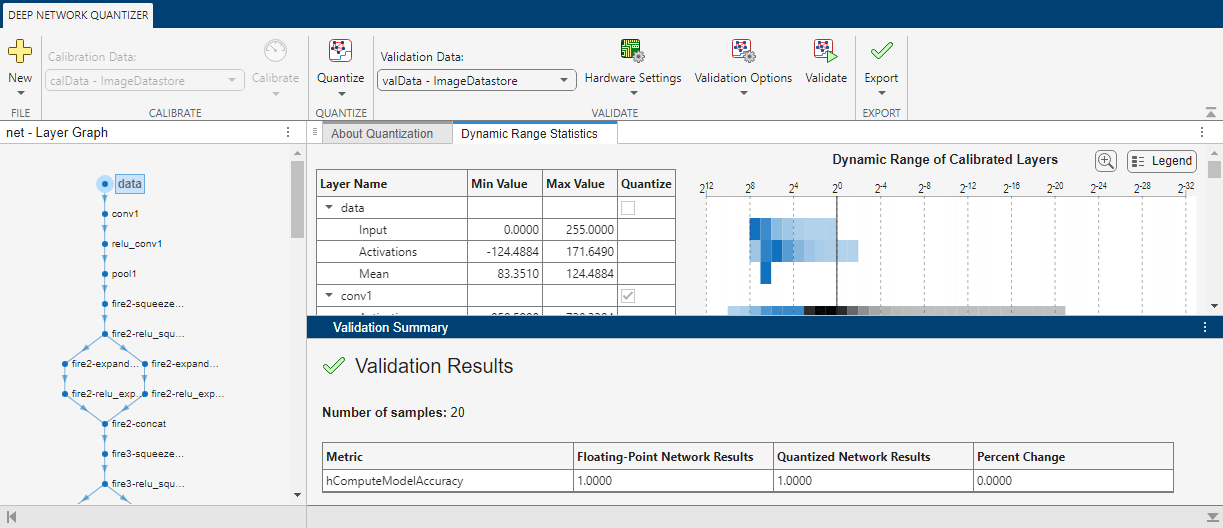
The Deep Network Quantizer uses the calibration data to exercise the network and collect range information for the learnable parameters in the network layers.
When the calibration is complete, the app displays a table containing the weights, biases, and activations for layers of the network and their minimum and maximum values during the calibration. To the right of the table, the app displays histograms of the dynamic ranges of the parameters.

In the Quantize section of the toolstrip, under Quantize, select the MinMax exponent scheme. Click Quantize.
The Deep Network Quantizer quantizes the weights, activations, and biases of layers in the network to scaled 8-bit integer data types. The app updates the histogram of the dynamic ranges of the parameters. The gray regions of the histograms indicate data that cannot be represented by the quantized representation. For more information on how to interpret these histograms, see Data Types and Scaling for Quantization of Deep Neural Networks.
In the Quantize column of the table, indicate whether to quantize the learnable parameters in the layer. Layers that are not quantized remain in single precision after quantization.

In the Validate section of the toolstrip, under Validation Data, select the ImageDatastore object from the base workspace containing the validation data, valData.
In the Validate section of the toolstrip, under Hardware Settings, select Raspberry Pi as the Simulation Environment. The app auto-populates the Target credentials from an existing connection or from the last successful connection. You can also use this option to create a new Raspberry Pi connection.

Define a custom metric function, hComputeModelAccuracy. Save this custom metric function in a local file.
function accuracy = hComputeModelAccuracy(predictionScores, ~, dataStore) %% Computes model-level accuracy statistics classNames = categories(dataStore.Labels); predictedLabels = scores2label(predictionScores,classNames); accuracy = mean(squeeze(predictedLabels) == dataStore.Labels); end
In the Validate section of the toolstrip, under Validation Options, enter the name of the custom metric function, hComputeModelAccuracy. Select Add to add hComputeModelAccuracy to the list of metric functions available in the app. Select hComputeModelAccuracy as the metric function to use.
The custom metric function must be on the path. If the metric function is not on the path, this step causes an error.

Click Validate. The app uses the validation data to exercise the network.
When the validation is complete, the app displays the results of the validation, including:
Metric function used for validation
Result of the metric function before and after quantization
Memory requirement of the network before and after quantization (MB)
If the performance of the quantized network is not satisfactory, you can explore the effects of choosing a different exponent selection scheme for quantization in the Quantize drop-down list. To see the effects of these changes, quantize and validate the network again.
After calibrating and quantizing the network, you can choose to export the quantized network or the dlquantizer object. Select the Export button. In the drop down, select from the following options:
Export Quantized Network — Add the quantized network to the base workspace. This option exports a simulatable quantized network that you can explore in MATLAB without deploying to hardware.
Export Quantizer — Add the
dlquantizerobject to the base workspace. You can save thedlquantizerobject and use it for further exploration in the Deep Network Quantizer app or at the command line, or use it to generate code for your target hardware.Generate Code — Open the MATLAB Coder app and generate C++ code from the quantized neural network. Generating C++ code requires a MATLAB Coder™ license.
Import a dlquantizer object from the base workspace into the
Deep Network Quantizer app to begin quantization of a deep neural network
using either the command line or the app, and resume your work later in the app.
Open the Deep Network Quantizer app.
deepNetworkQuantizer
In the app, click New and select Import
dlquantizer object.

In the dialog, select a dlquantizer object to import from the
base workspace. For this example, use the dlquantizer object
quantizer from the above example Quantize a Neural Network
for GPU Target. You can create the quantizer object by selecting
Export Quantizer from the Export
drop-down list after quantizing the network.

The app imports any data contained in the dlquantizer object that
was collected at the command line, including the quantized network, calibration
data, validation data, and calibration statistics.
The app displays a table containing the quantization data contained in the
imported dlquantizer object, quantizer. To the
right of the table, the app displays histograms of the dynamic ranges of the
parameters. The gray regions of the histograms indicate data that cannot be
represented by the quantized representation. For more information on how to
interpret these histograms, see Quantization of Deep Neural Networks.

Related Examples
Parameters
Limitations
Validation on target hardware for CPU, FPGA, and GPU execution environments is not supported in MATLAB Online™. For FPGA and GPU execution environments, perform validation through emulation on the MATLAB Online host.