Counterparty Risk Assessment with Two Steps: Monte Carlo and Parallel Computing
Pablo García Estébanez, Banco Sabadell
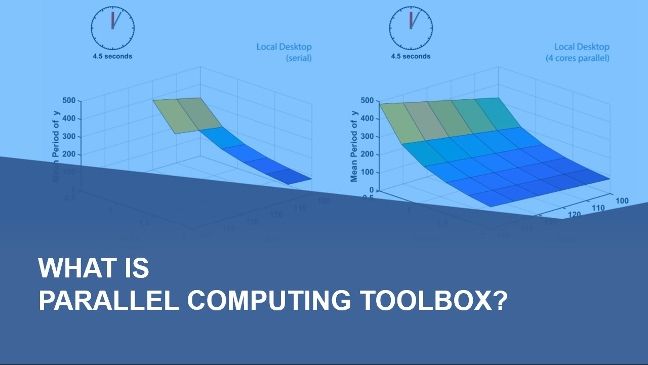
In this presentation, discover a novel approach to counterparty risk assessment using a two-step process: Monte Carlo simulations and parallel computing. This method leverages Monte Carlo simulations to model and quantify risk under various scenarios, followed by parallel computing to efficiently process and analyze large datasets. Learn how this integrated approach enhances the accuracy and speed of risk assessments, enabling more robust financial decision making. See practical examples and insights drawn from extensive experience in quantitative analysis and financial modeling.
Published: 22 Oct 2024