Optimize block operation order in generated code
Specify to reorder block operations for improved code execution speed
Model Configuration Pane: Code Generation / Optimization
Description
The Optimize block operation order in generated code parameter specifies to reorder block operations in the generated code for improved code execution speed.
Settings
Improved Code Execution Speed (default) | offoffEmbedded Coder® does not reorder block operation order in the generated code to create additional instances of buffer reuse.
Improved Code Execution SpeedEmbedded Coder changes the block operation order in the generated code so that more instances of buffer reuse can occur. Reusing buffers conserves RAM and ROM consumption and improves code execution speed.
Examples
This example show how to remove data copies by changing the
Optimize block order in the generated code parameter
from off to Improved Execution
Speed. Changing this setting indicates to the code generator
to reorder block operations where possible to remove data copies. This
optimization conserves RAM and ROM consumption.
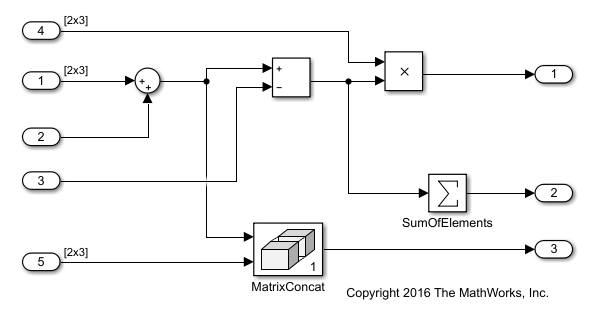
In the model ex_optimizeblockorder, the signal that
leaves the Sum block enters a Subtract block
and a Concatenate block. The signal that leaves the
Subtract block enters a Product block and
a Sum of Elements block.
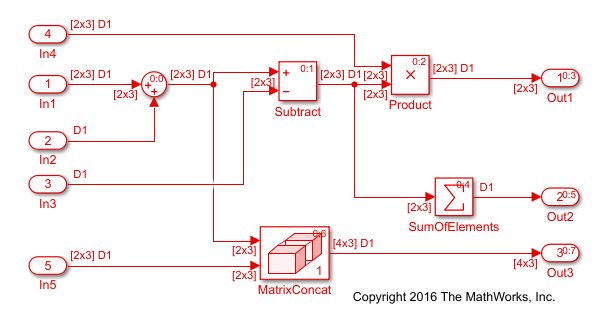
The image shows the model ex_optimizeblockorder after a
model build. The red numbers indicate the default block order in the
generated code. The Subtract block executes before the
Concatenate block. The Product block
executes before the Sum of Elements block.
View the generated code without the optimization. Here is the
ex_optimizeblockorder_step function.
/* Model step function */
void ex_optimizeblockorder_step(void)
{
real_T rtb_Sum2x3[6];
int32_T i;
real_T rtb_Sum2x3_d;
real_T rtb_Subtract;
/* Sum: '<Root>/SumOfElements' */
rtY.Out2 = -0.0;
for (i = 0; i < 6; i++) {
/* Sum: '<Root>/Sum2x3' incorporates:
* Inport: '<Root>/In1'
* Inport: '<Root>/In2'
*/
rtb_Sum2x3_d = rtU.In1[i] + rtU.In2;
/* Sum: '<Root>/Subtract' incorporates:
* Inport: '<Root>/In3'
*/
rtb_Subtract = rtb_Sum2x3_d - rtU.In3;
/* Outport: '<Root>/Out1' incorporates:
* Inport: '<Root>/In4'
* Product: '<Root>/Product'
*/
rtY.Out1[i] = rtU.In4[i] * rtb_Subtract;
/* Sum: '<Root>/Sum2x3' */
rtb_Sum2x3[i] = rtb_Sum2x3_d;
/* Sum: '<Root>/SumOfElements' */
rtY.Out2 += rtb_Subtract;
}
/* Concatenate: '<Root>/MatrixConcat ' */
for (i = 0; i < 3; i++) {
/* Outport: '<Root>/Out3' incorporates:
* Inport: '<Root>/In5'
*/
rtY.Out3[i << 2] = rtb_Sum2x3[i << 1];
rtY.Out3[2 + (i << 2)] = rtU.In5[i << 1];
rtY.Out3[1 + (i << 2)] = rtb_Sum2x3[(i << 1) + 1];
rtY.Out3[3 + (i << 2)] = rtU.In5[(i << 1) + 1];
}
/* End of Concatenate: '<Root>/MatrixConcat ' */
}With the default order, the generated code contains three buffers,
rtb_Sum2x3[6], rtb_Sum2x3_d, and
rtb_Subtract. The generated code contains these
temporary variables and associated data copies because the Matrix
Concatenate block must use the output from the
Sum block and the Sum of Elements block
must use the output from the Subtract block.
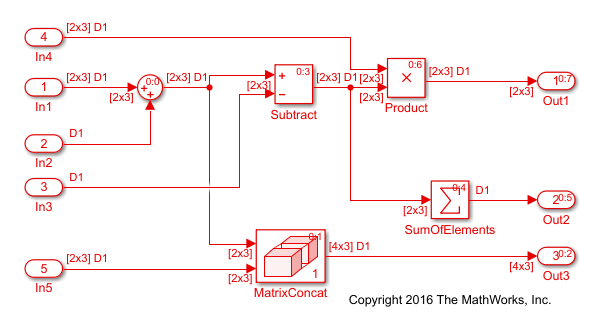
The image shows the ex_optimizeblockorder model after
setting the Optimize block operation order in generated
code parameter to Improved Execution
Speed and building the model. The Subtract
block executes after the Concatenate block. The
Product block executes after the Sum of
Elements block.
In the optimized code, the three buffers rtb_Sum2x3[6],
rtb_Sum2x3_d, and rtb_Subtract and
their associated data copies are gone. The generated code does not require
these temporary variables to hold the outputs of the Sum and
Subtract blocks because the Subtract block
executes after the Concatenate block and the
Product block executes after the Sum of
Elements block.
/* Model step function */
void ex_optimizeblockorder_step(void)
{
int32_T i;
/* Sum: '<Root>/Sum2x3' incorporates:
* Inport: '<Root>/In1'
* Inport: '<Root>/In2'
*/
for (i = 0; i < 6; i++) {
rtY.Out1[i] = rtU.In1[i] + rtU.In2;
}
/* End of Sum: '<Root>/Sum2x3' */
/* Concatenate: '<Root>/MatrixConcat ' */
for (i = 0; i < 3; i++) {
/* Outport: '<Root>/Out3' incorporates:
* Inport: '<Root>/In5'
*/
rtY.Out3[i << 2] = rtY.Out1[i << 1];
rtY.Out3[2 + (i << 2)] = rtU.In5[i << 1];
rtY.Out3[1 + (i << 2)] = rtY.Out1[(i << 1) + 1];
rtY.Out3[3 + (i << 2)] = rtU.In5[(i << 1) + 1];
}
/* End of Concatenate: '<Root>/MatrixConcat ' */
/* Sum: '<Root>/SumOfElements' */
rtY.Out2 = -0.0;
for (i = 0; i < 6; i++) {
/* Sum: '<Root>/Subtract' incorporates:
* Inport: '<Root>/In3'
*/
rtY.Out1[i] -= rtU.In3;
/* Sum: '<Root>/SumOfElements' */
rtY.Out2 += rtY.Out1[i];
/* Outport: '<Root>/Out1' incorporates:
* Inport: '<Root>/In4'
* Product: '<Root>/Product'
*/
rtY.Out1[i] *= rtU.In4[i];
}
}To implement buffer reuse, the code generator does not violate user-specified block priorities.
Recommended Settings
| Application | Setting |
|---|---|
| Debugging | No impact |
| Traceability | No impact |
| Efficiency | Improved Code Execution Speed |
| Safety precaution | No recommendation |
Programmatic Use
Parameter:
OptimizeBlockOrder |
| Type: character vector |
Value:
'speed' | 'off'
|
Default:
'speed' |
Version History
Introduced in R2017a