You Don't Always Need to Convert to Fixed Point for FPGA or ASIC Deployment
By Jack Erickson, Kiran Kintali, and Jonathan Young, MathWorks
MATLAB® and Simulink® use floating-point-based modeling to ensure high-accuracy calculations for algorithm simulation. Converting to fixed point reduces mathematical precision, and it can be challenging to strike the right balance between data type word lengths and mathematical accuracy during conversion. For calculations that require high dynamic range or high precision (for example, designs that have feedback loops), fixed-point conversion can consume weeks or months of engineering time and can result in large fixed-point word lengths.
Beginning with release R2016b, you can generate HDL code for FPGA or ASIC implementation directly from single-precision floating-point data in Simulink by using the HDL Coder™ Native Floating Point library. See video “Generate Floating-Point HDL for FPGA and ASIC Hardware” (below).
In this article we will introduce the native floating-point workflow, using an IIR filter deployed to an FPGA as an illustration. We will then review the challenges of using fixed point, and compare the area and frequency tradeoffs of using single-precision floating point or fixed point. We will also show how a combination of floating point and fixed point can give you much higher accuracy while reducing conversion and implementation time in real-world designs. You will see how floating-point can significantly reduce area and improve speed in real-world designs with high dynamic range requirements.
Native Floating-Point Implementation: Under the Hood
HDL Coder implements single-precision arithmetic by emulating the underlying math on the FPGA or ASIC resources (Figure 1). The generated logic unpacks the input floating-point signal into sign, exponent, and mantissa—individual integers that are 1, 8, and 23 bits wide, respectively. The generated VHDL® or Verilog® logic then performs the floating-point calculation—in the case shown in Figure 1, a multiplication—by figuring out the sign bit resulting from the input sign bits, the magnitude multiplication, and the addition of exponents and corresponding normalization necessary to compute the result. The last stage of the logic packs the sign, exponent, and mantissa back into a floating-point data type.

Figure 1. How HDL Coder maps a single-precision floating-point multiplication to fixed-point hardware resources.
HDL Coder does all this automatically for your single-precision operations when you choose the “Native Floating Point Library” code generation option in the HDL Workflow Advisor. You can also set options that provide more control over how the floating-point operations are implemented in hardware, such as targeting a specific latency, targeting specific DSP logic on an FPGA. HDLCoder also provides options to flush denormal to zero, and efficiently handle INFs and NaNs.
Tackling Dynamic Range Issues with Fixed-Point Conversion
A simple expression like 1-a/1+a, if it needs to be implemented with high dynamic range, can be translated naturally by using single precision (Figure 2).

Figure 2. Single-precision implementation of (1-a)/(1+a).
However, implementing the same equation in fixed point requires many steps and numerical considerations (Figure 3). For example, you have to break the division into multiplication and reciprocal, use approximation methods such as newton-raphson or LUT for nonlinear reciprocal operation, use different data types to carefully control the bit growth, select the proper numerator and denominator types, and use specific output types and accumulator types for the adders and subtractors.

Figure 3. Fixed-point implementation of (1-a)/(1+a).
Exploring IIR Implementation Options
Let’s look at an infinite impulse response (IIR) filter example. An IIR filter requires high dynamic range calculation with a feedback loop, making it tricky to converge on a fixed-point quantization. Figure 4a shows a test environment comparing three versions of the same IIR filter with a noisy sine wave input. The sine wave has an amplitude of 1, and the added noise increases the amplitude slightly. The first version of the filter is double precision (Figure 4b). The second version is single precision. The third version is a fixed-point implementation (Figure 4c). This implementation resulted in data types up to 22 bits in word length, with 1 bit allocated for the sign and 21 bits allocated for the fraction. This particular data type leaves 0 bits to represent the integer value, which makes sense given that its range of values will always be between -1 and 1 for the given stimulus. If the design has to work with different input values, that needs to be taken into account during fixed-point quantization.

Figure 4. a. Three implementations of an IIR filter with noisy sine wave input.
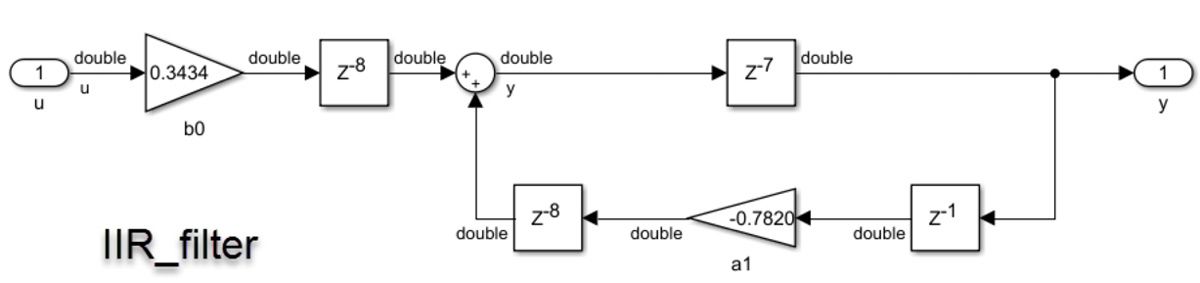
Figure 4b. IIR_filter implementation, shown with double-precision data types.

Figure 4c. IIR_filter_fixpt implementation, which uses fixed-point data types that are signed, 18-bit word length, with 16 of those bits for the fraction length.
The test environment is set up to compare the results of the single-precision and fixed-point filters with the double-precision filter, which is considered the golden reference. In both cases, a loss of precision will yield a certain amount of error. The question is whether that error is within an acceptable tolerance for our application.
When we ran Fixed-Point Designer™ to perform the conversion, we specified an error tolerance of 1%. Figure 5 shows the results of the comparisons. The error for the single-precision version is on the order of 10-8, while the fixed-point data type is on the order of 10-5. This is within the error tolerance we specified. If your application needs higher precision, you may need to increase your fixed-point word lengths.

Figure 5. Simulation results comparing the double-precision IIR filter results with the single-precision results (top) and fixed-point results (bottom).
Converging on this quantization takes experience with hardware design, a comprehensive understanding of the possible system inputs, clear accuracy requirements, and some assistance from Fixed-Point Designer. This effort is worthwhile if it helps you shrink your algorithm for production deployment. But what about cases where you need to simply deploy to prototype hardware, or where the accuracy requirements make it difficult to reduce the physical footprint?
A solution in these cases is to use single-precision native floating point.
Simplifying the Process with Native Floating Point
Using native floating point has two benefits:
- You don’t have to spend time trying to analyze the minimum number of bits needed to maintain enough precision for a wide variety of input data.
- The dynamic range of single-precision floating-point operations scales much more efficiently with a fixed cost of 32 bits.
Now the design process is much simpler, and you know that with the bits of sign, exponent, and mantissa you can represent a wide dynamic range of numbers. The table in Figure 6 compares the resource utilization of the floating-point and the fixed-point implementations of the IIR filter using the data type choices shown in Figure 5.

Figure 6. Resource usage comparison between the fixed-point and floating-point implementations of the IIR filter.
When you compare the results obtained from the floating-point and fixed-point implementations, remember that floating-point calculations require more operations than simple fixed-point arithmetic. Using single precision will result in higher physical resource usage when you deploy to an FPGA or ASIC. If circuit area is a concern, then you will need to trade off higher precision and resource usage. You can also use a combination of floating point and fixed point to reduce area while preserving single precision to achieve high dynamic range in numerically intensive computation islands.
Managing Resource Usage with Native Floating Point
Native floating point is an easy way to generate code for a high dynamic range application to program an FPGA or deploy to an ASIC. But if native floating point exceeds your resource budget, there are several ways to reduce resource usage:
- Use HDL Coder optimizations. Resource sharing and other algorithm-level optimizations support native floating-point code generation. These optimizations can, for example, reduce area by sharing complex mathematical operations that consume significant area, such as
exp,atan2through time-division multiplexing and other sharing and streaming techniques. - Use the fixed-point conversion process where appropriate. Fixed-point conversion is straightforward for designs without high dynamic range requirements or feedback loops, and Fixed-Point Designer helps automate this process. In some types of design, achieving convergence without adding extra bits can be difficult. In such cases, using selective applications of native floating point is a better choice. This method uses fixed-point conversion for most of the design while allowing you to use floating point in high dynamic range portions of the data path.
- Create floating-point and fixed-point “islands” in the design. Once you have identified the portions of your design where it will be challenging to achieve convergence, you can isolate them by using Data Type Conversion blocks that convert the inputs to single precision and then converting the outputs of the operation back to the appropriate fixed-point type. Figure 7 shows a portion of a motor control design where a gain operation and a sincos operation are isolated as a native floating-point region, with the output converted back to a fixed-point value.

Figure 7. Mixing fixed point and native floating point in the same design.
Here is a quick guide to selecting floating-point or fixed-point in your design:
Use floating point for your whole design if:
- You lack experience with fixed-point quantization.
- Your algorithm has a mix of very large and very small numbers.
- Your design extensively uses fixed-point types greater than 32-bits.
- Your design includes nonlinear operations such as
divide,mod,rem,log,exp, andatan, which are hard to convert to fixed point. - You have flexibility to use greater area and latency (e.g., in lower-bandwidth applications such as motor control or audio processing).
Use fixed point for your whole design if:
- You are experienced in fixed-point quantization.
- Converting your algorithm to fixed point is straightforward.
- You have strict area and latency requirements.
Mix floating and fixed point if:
- Your design has a mix of control logic and data path with large dynamic range.
- Only a portion of the design is challenging to quantize to fixed point.
- You have enough margin in your area requirements for limited use of floating-point arithmetic.
A Real-World Example Using Native Floating Point
As Figure 8 shows, if you are dealing with dynamic range problems and moving toward longer word lengths, your fixed-point implementation can consume significantly more resources than the floating-point version.

Figure 8. Sqrt function resource utilization. At greater word lengths, sqrt consumes more FPGA resources than a single-precision implementation, which has fixed cost.
To see how native floating point can come into play in a case like this, consider this example of an electric vehicle model (Figure 9). This is a complex model incorporating many components, including a battery model, an inverter, a PMSM, and a vehicle model.
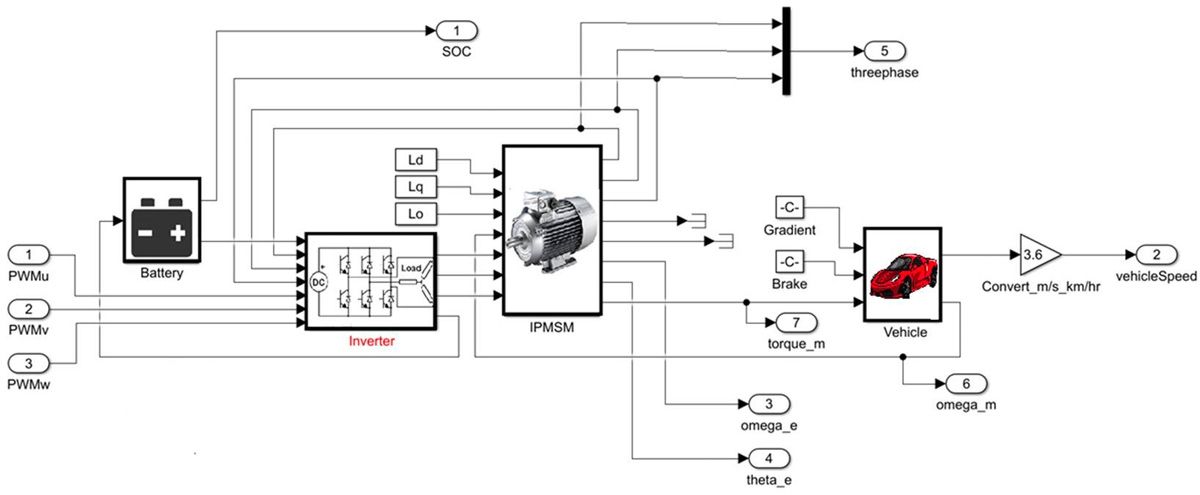
Figure 9. Electric vehicle model.
Figure 10 shows the mathematical equations used to implement these components.

Figure 10. Mathematical equations used in the electrical vehicle model.
Targeting such a model to hardware with fixed point is likely to be challenging because of all the feedback loops between the components. It could take months to figure out how to reduce the quantization errors in a system of components with complex feedback loops between PMSM and inverter. To reduce error, you have to use very large word lengths. With floating-point support, however, you can directly target this model on hardware without converting it to fixed point.
As Figure 11 shows, floating point is the right choice of data type for an algorithm with feedback loops—the floating-point implementation uses less area and performs better, as the fixed-point version of the same algorithm requires large word lengths.

Figure 11. Comparison of fixed-point and floating-point implementations of the electric vehicle model.
Conclusion
Fixed-point quantization has traditionally been one of the most challenging tasks in adapting an algorithm to target FPGA or ASIC hardware. Native floating-point HDL code generation allows you to generate VHDL or Verilog for floating-point implementation in hardware without the effort of fixed-point conversion. This approach can save a lot of time if you are creating an FPGA implementation, and it can be a faster way to target algorithms to a Xilinx® Zynq® SoC or an Intel® SoC FPGA.
For designs that require the best of both worlds—the control logic of fixed point and the high dynamic range data path of floating point—you can easily combine the two.
Published 2018